StarGAN: Unified Generative Adversarial Networks for Multi
最近在两个领域上的图像翻译研究取得了显著的成果。但是在处理多于两个领域的问题上,现存的方法在尺度和鲁棒性上还是有所欠缺,因为需要为每个图像域对单独训练不同的模型。为了解决该问题,我们提出了StarGAN方法,这是一个新型的可扩展的方法,能够仅使用一个单一模型就实现多领域的图像翻译。StarGAN这样的统一模型的结构允许在单个网络上同时训练带有不同领域的多个数据集。这使得StarGAN的翻译图像质量优于现有的模型,并具有将输入图像灵活地翻译到任意目标域的新能力。通过实验,验证了该方法在人脸属性转移和表情合成任务上的有效性。
1. Introduction
图像翻译的任务是改变给定图像的某一方面,例如,改变一个人的面部表情从微笑到皱眉(见图1)。这个任务在生成对抗网络(GANs)的介绍后得到了重大改善,从改变头发颜色[9],重建照片的边缘[7]到改变风景图片的季节[33]。
给定来自两个不同领域的训练数据,这些模型学习将图像从一个领域转换到另一个领域。我们将属性
attribute一词表示为图像中固有的有意义的特性,如头发颜色、性别或年龄,属性值attribute value表示属性的特定值,如头发颜色为黑色/金色/棕色,性别为男性/女性。我们进一步将域domain表示为一组共享相同属性值的图像。例如,女性的图像可以代表一个领域,而男性的图像则代表另一个领域。
一些图像数据集带有许多标记的属性。例如,CelebA[19]数据集包含40个与面部属性相关的标签,如头发颜色、性别和年龄;RaFD[13]数据集包含8个用于面部表情的标签,如“高兴”、“生气”和“悲伤”。这些集合使我们能够执行更有趣的任务,即多域图像到图像的转换,即根据来自多个域的属性更改图像。图1的前五列显示了如何根据“金发”、“性别”、“年龄”和“苍白皮肤”这四个域中的任意一个来翻译名人图片。我们可以进一步从不同的数据集中训练多个域,例如联合训练CelebA和RaFD图像,利用RaFD上训练得到的特征来改变一个CelebA图像的面部表情,如图1最右栏所示:

然而,现有的模型在多域图像翻译任务中效率低下,效果不好。它们效率低下的原因是,为了学习k个域之间的所有映射,必须训练k(k−1)个生成器。图2 (a)说明了如何训练12个不同的生成网络来在4个不同的域中转换图像:
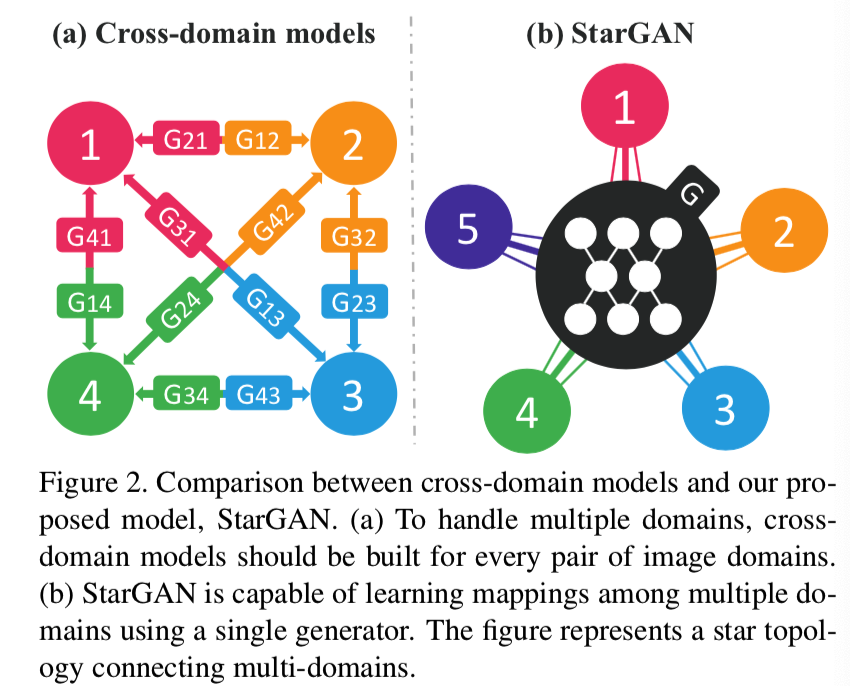
同时,他们效果也是不好的,尽管存在可以从所有领域的图像中学习得到的全局特征,如脸型,但是每个生成器不能充分利用整个训练数据,只能使用对应的两个域的图像。不能完全利用训练数据可能会限制生成图像的质量。此外,它们无法从不同的数据集中联合训练域,因为每个数据集都是部分标记,该内容我们将在第3.2节中进一步讨论。
为了解决这些问题,我们提出了StarGAN,这是一种新颖的、可扩展的方法,,能够学习多个域之间的映射。如图2 (b)所示,我们的模型接受多个域的训练数据,仅使用一个生成器学习所有可用域之间的映射。想法很简单。我们的生成器不是学习固定的翻译(例如,从黑色到金色的头发),而是将图像和域信息作为输入,并灵活地学着将图像转换为相应的域。我们使用一个标签(例如,二进制或一个one-hot向量)来表示域信息。在训练过程中,我们随机生成目标域标签,并训练模型将输入图像灵活地转换到目标域。通过这样做,我们可以控制域标签并在测试阶段将图像翻译到任何想要的域。
我们还介绍了一种简单但有效的方法,通过向域标签添加掩码向量来实现不同数据集域之间的联合训练。我们提出的方法确保模型可以忽略未知的标签,而专注于特定数据集提供的标签。通过这种方式,我们的模型可以很好地完成一些任务,例如使用RaFD中学习到的特征来合成CelebA图像的面部表情,如图1最右边的列所示。据我们所知,我们的工作是第一个成功地执行跨不同数据集的多域图像转换。
总之,我们的贡献如下:
我们提出了StarGAN,一个新的生成式对抗网络,它能从所有域的图像中有效地训练,只使用一个生成器和一个识别器就能学习多个域之间的映射。
我们演示了如何利用掩模向量方法成功地学习多个数据集之间的多域图像转换,该方法使StarGAN能够控制所有可用的域标签。
我们使用StarGAN提供了面部属性转移和面部表情合成识别任务的定性和定量结果,表明其优于基线模型。
2. Related Work
温馨提示: 本文由Jm博客推荐,转载请保留链接: https://www.jmwww.net/file/web/42467.html
- 上一篇:layui form ajax提交
- 下一篇:weblogic添加项目

![[转]Node.js中package.json中^和~的区别](/uploads/allimg/200519/054J34453_lit.png "[转]Node.js中package.json中^和~的区别")