Pytorch中的自编码(autoencoder)
先压缩原数据、提取出最有代表性的信息。然后处理后再进行解压。减少处理压力
通过对比白色X和黑色X的区别(cost函数),从而不断提升自编码模型的能力(也就是还原的准确度)
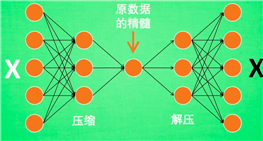
由于这里只是使用了数据本身,没有使用label,所以可以说autoencoder是一种无监督学习模型。
实际在使用中,我们先训练好一个autoencoder模型,然后只取用其前一半,来获取到压缩了的特征进行其他的训练,以达到压缩特征的目的。
自编码可以达到类似于PCA的效果
自编码in Pytorchencoder
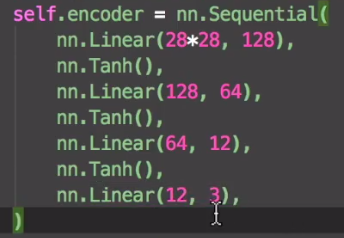
decoder

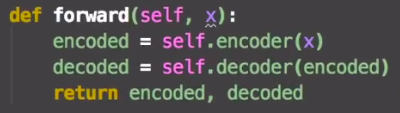
连接成网络
设置优化器和损失函数
autoencoder=AutoEncoder() optimizer=torch.optim.Adam(autoencoder.parameters(),lr=LR) loss_func=mm.MSELoss()搭建网络,,传入数据
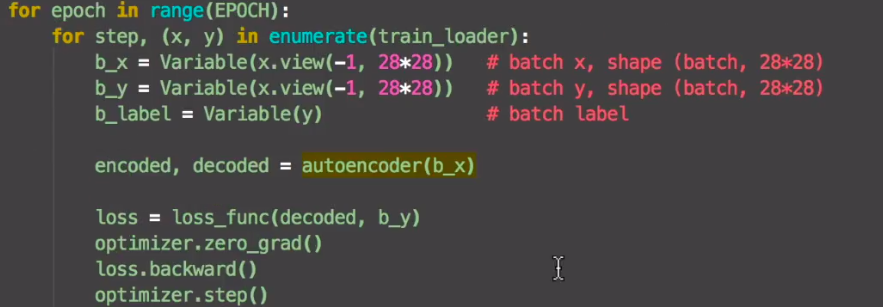
这里的y是压缩之前的数据,用来在loss function中和decoded对比的
设置输出
Pytorch中的自编码(autoencoder)
温馨提示: 本文由Jm博客推荐,转载请保留链接: https://www.jmwww.net/file/web/42396.html

![[转]Node.js中package.json中^和~的区别](/uploads/allimg/200519/054J34453_lit.png "[转]Node.js中package.json中^和~的区别")