Key concepts on Deep Neural Networks(第四周 测验 – 深层神经网络)
标签:
Week 4 Quiz - Key concepts on Deep Neural Networks(第四周 测验 – 深层神经网络)\1. What is the “cache” used for in our implementation of forward propagation and backward propagation?(在实现前向传播和反向传播中使用的“cache”是什么?)
【 】It is used to cache the intermediate values of the cost function during training.(用于在训练期间缓存成本函数的中间值。)
【 】We use it to pass variables computed during forward propagation to the corresponding backward propagation step. It contains useful values for backward propagation to compute derivatives.(我们用它传递前向传播中计算的变量到相应的反向传播步骤,它包含用于计算导数的反向传播的有用值。)
【 】It is used to keep track of the hyperparameters that we are searching over, to speed up computation.(它用于跟踪我们正在搜索的超参数,以加速计算。)
【 】We use it to pass variables computed during backward propagation to the corresponding forward propagation step. It contains useful values for forward propagation to compute activations.(我们使用它将向后传播计算的变量传递给相应的正向传播步骤,它包含用于计算计算激活的正向传播的有用值。)
答案【★】We use it to pass variables computed during forward propagation to the corresponding backward propagation step. It contains useful values for backward propagation to compute derivatives.(我们用它传递前向传播中计算的变量到相应的反向传播步骤,它包含用于计算导数的反向传播的有用值。)
Note: the “cache” records values from the forward propagation units and sends it to the backward propagation units because it is needed to compute the chain rule derivatives.(请注意:“cache”记录来自正向传播单元的值并将其发送到反向传播单元,因为需要链式计算导数。)
?
\2. Among the following, which ones are “hyperparameters”? (Check all that apply.)(以下哪些是“超参数”?)
【 】size of the hidden layers \(??^{[??]}\) (隐藏层的大小\(??^{[??]}\))
【 】learning rate α(学习率 α)
【 】number of iterations(迭代次数)
【 】number of layers ?? in the neural network(神经网络中的层数??)
答案全对
Note: You can check this Quora post or this blog post.(请注意:你可以查看 Quora 的这篇文章 或者 这篇博客.)
?
\3. Which of the following statements is true?(下列哪个说法是正确的?)
【 】The deeper layers of a neural network are typically computing more complex features of the input than the earlier layers. (神经网络的更深层通常比前面的层计算更复杂的输入特征。) 【 】 The earlier layers of a neural network are typically computing more complex features of the input than the deeper layers.(神经网络的前面的层通常比更深层计算更复杂的输入特征。)
答案【★】The deeper layers of a neural network are typically computing more complex features of the input than the earlier layers. (神经网络的更深层通常比前面的层计算更复杂的输入特征。)
Note: You can check the lecture videos. I think Andrew used a CNN example to explain this.(注意:您 可以查看视频,我想用吴恩达的用美国有线电视新闻网的例子来解释这个。)
?
\4. Vectorization allows you to compute forward propagation in an ??-layer neural network without an explicit for-loop (or any other explicit iterative loop) over the layers l=1, 2, …,L. True/False?(向量化允许您在??层神经网络中计算前向传播,而不需要在层(l = 1,2,…,L)上显式的使用 for-loop(或任何其他显式迭代循环),正确吗?)
【 】 True(正确) 【 】 False(错误)
答案【★】 False(错误)
Note: We cannot avoid the for-loop iteration over the computations among layers.(请注意:在层间 计算中,我们不能避免 for 循环迭代。)
?
\5. Assume we store the values for \(??^{[??]}\) in an array called layers, as follows: layer_dims = \([??_??, 4,3,2,1]\). So layer 1 has four hidden units, layer 2 has 3 hidden units and so on. Which of the following for-loops will allow you to initialize the parameters for the model?(假设我们将 \(??^{[??]}\)的值存储在名为 layers 的数组中,如下所示:layer_dims =\([??_??, 4,3,2,1]\)。 因此,第 1 层有四个隐藏单元,第 2 层有三个隐藏单元,依此类推。您可以使用哪个 for 循环初始化模型参 数?)
答案for(i in range(1, len(layer_dims))):
parameter[‘W’ + str(i)] = np.random.randn(layers[i], layers[i- 1])) * 0.01
parameter[‘b’ + str(i)] = np.random.randn(layers[i], 1) * 0.01
?
\6. Consider the following neural network.(下面关于神经网络的说法正确的是:)
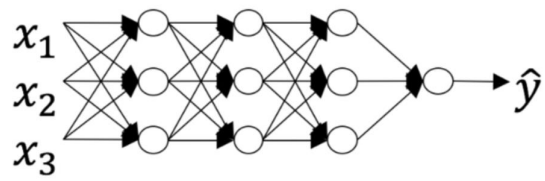
【 】The number of layers?? is 4. The number of hidden layers is 3.(层数??为 4,隐藏层数为 3)
答案显然
温馨提示: 本文由Jm博客推荐,转载请保留链接: https://www.jmwww.net/file/web/40219.html
- 上一篇:一些php常用函数积累
- 下一篇:ajax跨域(跨源)方案之CORS

![[转]Node.js中package.json中^和~的区别](/uploads/allimg/200519/054J34453_lit.png "[转]Node.js中package.json中^和~的区别")