结构化网页内容抽取方法
为了从几个网站抽取内容,聚合到一起。我于2012年写了一个程序,从多个网站通过结构化方法抽取内容。然后写入数据库,形成一个网站。
(1)正则表达式抽取
首先,从数据库中读取内容抽取规则:
ArrayList<RuleBean> rbList = ruleDao.QueryAllRule();
表结构如下:
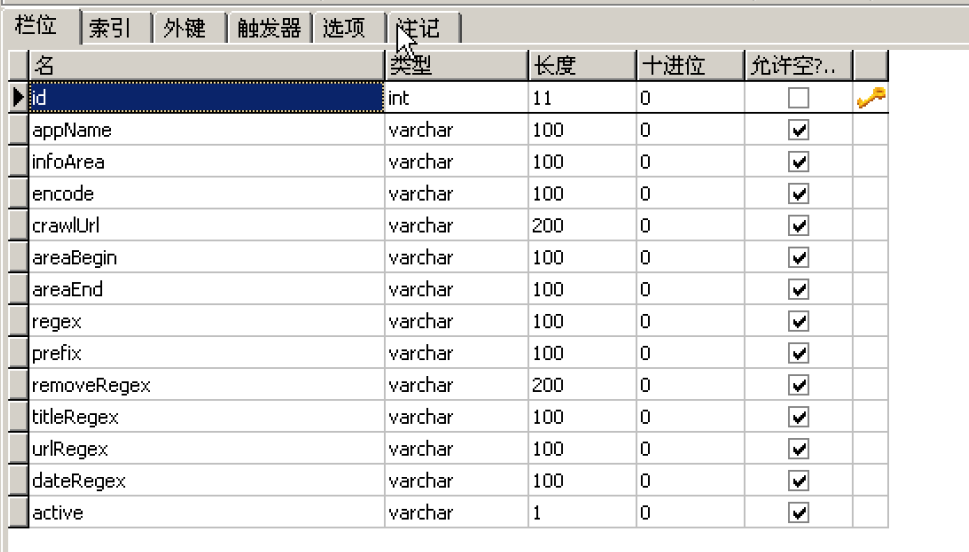
配置的抽取规则如下:
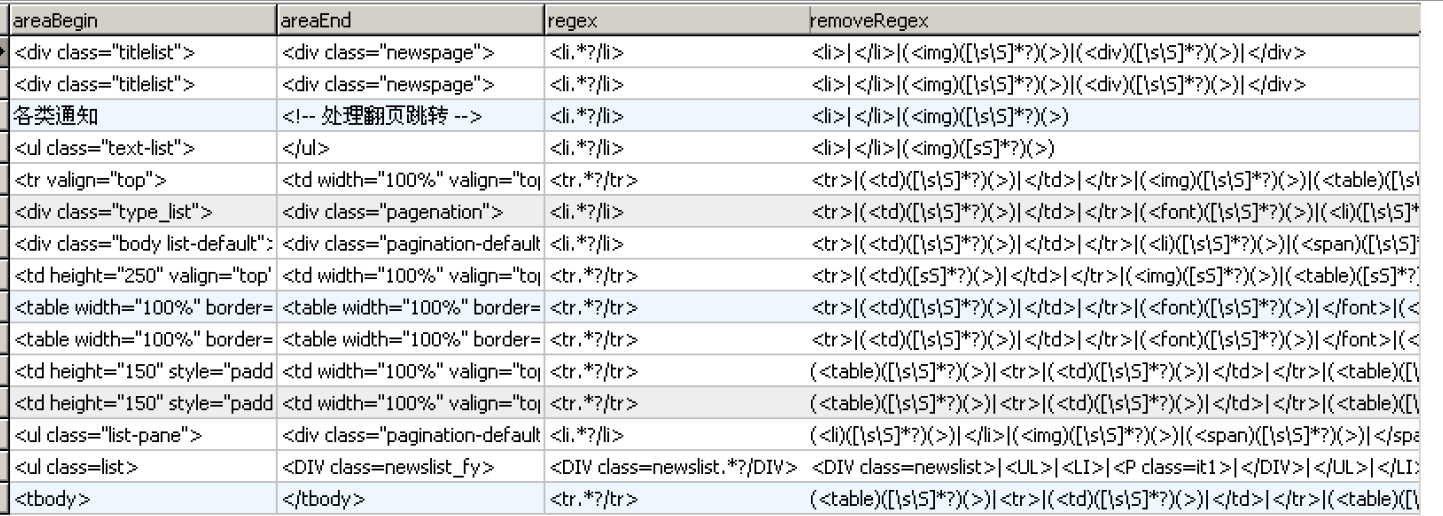
其次,读取网页内容,并通过起始标签抽取出内容,然后通过正则表达式读取出网址URL、标题和发表时间。
直接上代码如下:
private static void doCrawl(RuleBean rb) {
String urlContent = getUrlContent(rb.getCrawlUrl(),rb.getEncode());
if("error".equalsIgnoreCase(urlContent)){
return;
}
String contentArea = getContentArea(urlContent, rb.getAreaBegin(),
rb.getAreaEnd());
Pattern pt = Pattern.compile(rb.getRegex());
Matcher mt = pt.matcher(contentArea);
TitleAndUrlBean tuBean;
while (mt.find()) {
tuBean = new TitleAndUrlBean();
tuBean.setAppName(rb.getAppName());
tuBean.setInfoArea(rb.getInfoArea());
String rowContent = mt.group();
rowContent = rowContent.replaceAll(rb.getRemoveRegex(), "");
// 获取标题
Matcher title = Pattern.compile(rb.getTitleRegex()).matcher(
rowContent);
while (title.find()) {
String s = title.group().replaceAll("<u>|</u>|>|</a>|\\[.*?\\]|</l>","");
if(s ==null || s.trim().length()<=0){
s = "error";
}
tuBean.setTitle(s);
}
// 获取网址
Matcher myurl = Pattern.compile(rb.getUrlRegex()).matcher(
rowContent);
while (myurl.find()) {
String u = myurl.group().replaceAll(
"href=|\"|>|target=|_blank|title", "");
u = u.replaceAll("\‘|\\\\", "");
if(u!=null && (u.indexOf("http://")==-1)){
tuBean.setUrl(rb.getPrefix() + u);
}else{
tuBean.setUrl(u);
}
}
if(tuBean.getUrl() ==null){
tuBean.setUrl("error");
}
// 获取时间
Matcher d = Pattern.compile(rb.getDateRegex()).matcher(rowContent);
while (d.find()) {
tuBean.setDeliveryDate(d.group());
}
boolean r = TitleAndUrlDAO.Add(tuBean);
if (r){
log.info("crawl add " + tuBean.getAppName() + "_"
+ tuBean.getInfoArea()+"_"+tuBean.getTitle());
if(tuBean.getAppName().contains("jww")){
Cache cTeach = CacheManager.getCacheInfo("index_teach");
if(cTeach!=null){
温馨提示: 本文由Jm博客推荐,转载请保留链接: https://www.jmwww.net/file/web/38924.html

![[转]Node.js中package.json中^和~的区别](/uploads/allimg/200519/054J34453_lit.png "[转]Node.js中package.json中^和~的区别")