下:来自GSM-FR audio的语谱图
大规模的移动通信系统往往包罗传统的通信传输信道,存在窄带瓶颈,从而孕育产生具有电话质量的音频。在高质量的解码器存在的情况下,由于网络的规模和异构性,用现代高质量的音频解码器来传输高采样率的音频在实践中是很困难的。本文提出了一种在通信节点可以通过低速率编解码器来扩展带宽的要领。为此,我们提出了一个基于对数-梅尔谱图的模型,该模型以8 kHz的带宽受限语音信号和GSM-full-rate(FR)压缩的伪信号为条件来重建高辨别率的信号。在我们的MUSHRA评料中,我们表白,颠末训练可以 从 通过8kHz GSMFR编解码器的音频 中 上采样到24kHz语音信号的模型,能够重构质量稍低于16kHz自适应多速率带宽音频编解码器(AMRWB) 编解码器的音频,然后封锁 原始编码信号和以24kHz采样的原始语音之间的感知质量差距约莫有一半。 我们进一步证明,当通过同一模型时,未经压缩的8kHz音频可以在不异的MUSHRA评料中再次重建质量比16kHz AMR-WB更好的音频。
关键词:WaveNet、带宽扩展、超辨别率、生成模型
1、介绍及相关事情传统的传输信道仍然是许多大型通信系统的一部分。这些通道引入瓶颈,限制了带宽和语音质量。凡是这被称为电话质量音频。将根本布局的所有部分升级为与更高质量的音频编解码器兼容可能很困难。因此,本文提出了一种不升级根本设施的所有通信节点的要领,此中通信节点可以取代扩展任何传入语音信号的带宽。为了实现这一方针,我们提出了一个基于WaveNet的模型[1],一个音频波形的深度生成模型。
WaveNet被证明在基于语言特征的高质量语音合成中长短常有效的。别的,WaveNet体系布局已被用于文本到语音的log-mel谱图[2]和语音编码的其他低维潜在暗示[3,4]。考虑到wavenet体系布局从约束条件暗示中生成高质量语音的能力,我们将此技术扩展到语音的带宽扩展(BWE)[5]问题,也称为音频超辨别率[6]。
虽然BWE可以被理解为将带限信号扩展到低频和高频区域,但在这种情况下,我们对电话应用出格感兴趣,此中音频凡是通过低速率语音编解码器,如GSM全速率(FR)[7],它将重建信号的最高频率分量限制在4kHz以下,从而导致音频质量降低和潜在的可懂度损害。因此,我们着重于从采样率为8kHz的输入信号重建采样率为24kHz的信号。过去,带宽扩展是在语音的声码器暗示范围中进行的,使用的技术有高斯混合模型和隐马尔可夫模型[5];比来,人们越来越存眷使用神经网络来建模频谱包络[8]或直接预测上采样波形[6、9、10],比以前的要领更能提高质量。
在我们的尝试评料中,我们评估了我们提出的模型对窄带信号执行带宽扩展的能力。为了说明我们的事情所孕育产生的影响,我们展示了一个颠末训练的模型,在8kHz时将通过GSM-FR编解码器的语音信号提升到24kHz,能够重建与16kHz时自适应多速率宽带编解码器(AMR-WB)[11]孕育产生的音频质量相似或更好的音频。GSM-FR是传统GSM移动电话中使用的编解码器,而AMR-WB则是高清语音通话中常用的编解码器。虽然很难与以前的事情进行对照,但由于缺乏可反复的代码和差此外测试集划分,我们的要领在MUSHRA评料中获得了比以前的事情更高的分数[6]。
值得一提的是,我们相信我们的WaveNet内核可能会被更高效的计算架构所代替,如并行WaveNet[12]、WaveGlow[13]或WaveRNN[14]。这些体系布局已经表白,在连结相似的建模性能的同时,凡是可以重现更易于计算的模型版本。在这项事情中,我们成立了一个基于WaveNet的高质量带宽扩展观点的证明,因为它具有优越的暗示能力和相对容易的训练,使得使用其他更易于计算的架构来再现功效的可能性成为可能。
2、训练法式 2.1 模型架构WaveNet是一个生成模型,它将波形$x=\{x_1,...,x_T\}$的级联概率建模为条件概率的乘积,该条件是在先前timesteps给定的样本下给出的。条件WaveNet模型给与一个附加的输入变量$h$,并将该条件漫衍建模为
$$p(\mathbf{x} | \mathbf{h})=\prod_{t=1}^{T} p\left(x_{t} | x_{1}, \ldots, x_{t-1}, \mathbf{h}\right)$$
此任务中使用了条件WaveNet模型。条件输入$h$通过由五个扩张(dilated)卷积层构成的‘条件仓库‘,接着是两个转置(transpose)卷积,其效果是将条件输入的上采样因子增加四倍。自回归(Autoregressive)输入在[-1,1]范畴内被标准化,并通过滤波器尺寸为4和512的卷积层。然后,它们被输入到核心WaveNet模型中,WaveNet模型有三层,每层包孕10个扩张(dilated)卷积层,具有跳跃连接,就像原始WaveNet体系布局中一样[1]。我们使用的扩张(dilation)因子是2;滤波器的巨细和数目分袂是3和512。Skip connection的输出通过两个卷积层,每个卷积层有256个滤波器。样本值上的输出漫衍使用10个分量的量化逻辑混合(quantized logistic mixture)[15]建模。
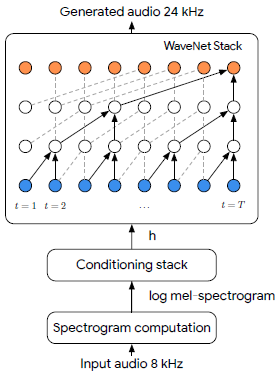
图2:措置惩罚惩罚过程的说明。将8khz采样的输入音频被转换成对数mel频谱暗示,
然后作为WaveNet条件仓库中的输入。该模型输出高采样率24khz的音频和更高的频率预测从其余的信号。
2.2 数据筹备温馨提示: 本文由Jm博客推荐,转载请保留链接: https://www.jmwww.net/file/web/33006.html

![[转]Node.js中package.json中^和~的区别](/uploads/allimg/200519/054J34453_lit.png "[转]Node.js中package.json中^和~的区别")