""); 12 13 u = u.replaceAll("‘|\\"
上篇文章,介绍了我2012年实现的一个内容聚合网站,通过正则表达式抽取网页内容,并供给了代码实现。
从网页中通过正则表达式获取标题、URL和发表时间
本文将进一步介绍其实现过程:
(1)网页布局分析
在2012年摆布,JavaScript还远没有今天这么强大,其时html是网页的骨架,css进行气势派头装饰,javascript供给行动。
[注]在当今动辄 React、Angular、Vue之类技术做前端,前端一栈式开发的配景下,内容抽取也许大不一样。
从网页页面上抽取内容,需要分析其html布局。一般情况下是通过table、ul、li、div之类的标签供给一个列表,内容页面一般是通过div实现的。
好比博客园的“精华区”,通过Chrome的F12,
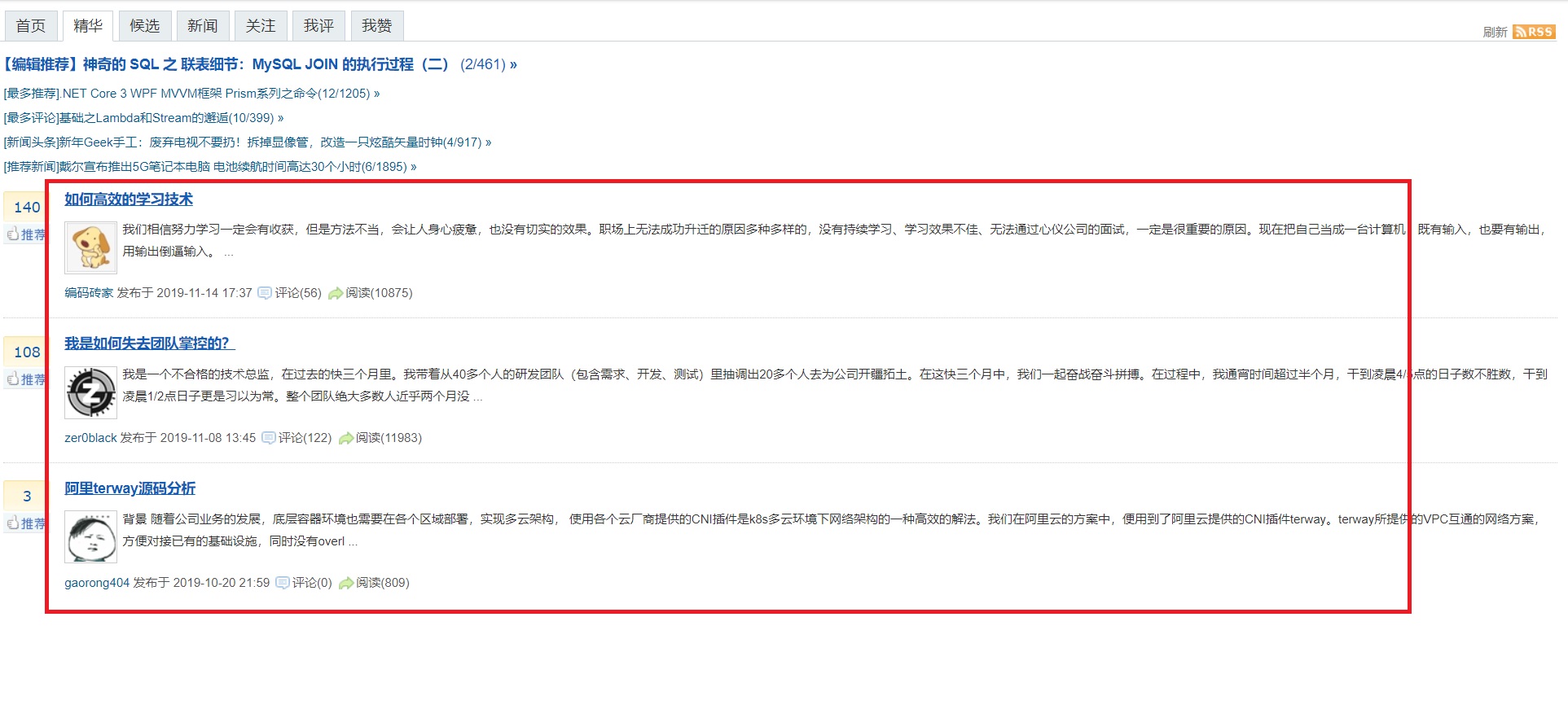
然后“检察元素”,整个列表页面是通过div支撑起来的,每一条也是一个div;
此中标题和链接是在<div>下的<a中;
发表时间,是在<a href=http://www.mamicode.com/和<span>之间。
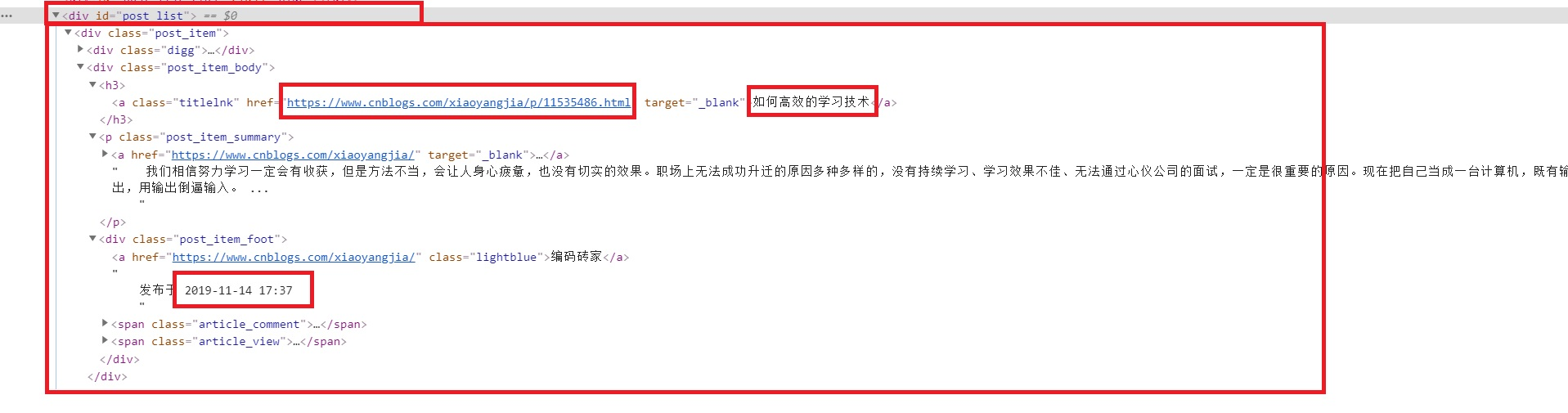
(2)内容提取
知道了布局,,下一步就是如何提取内容了。
提取整个列表部分
该部分相比拟较简单,找到列表部分的起始、结束部分就可以了。
如博客园精华部分的起始是:<div>,结束是:</div>。
一般情况下,开始位置对照容易确定,但结束位置这么些用正则表达式在结束标签是div的时候是无法获取内容的。这种情况下要找到结束标签的下一个标签,
好比:
<script>editorPickStat(); aggSite.user.getUserInfo();</script>
1 // 获得网址地址的匹配区域部分 2 3 private static String getContentArea(String urlContent, String strAreaBegin,String strAreaEnd) { 4 5 ? int pos1 = 0, pos2 = 0; 6 ? pos1 = urlContent.indexOf(strAreaBegin) + strAreaBegin.length(); 7 ? pos2 = urlContent.indexOf(strAreaEnd, pos1); 8 ? return urlContent.substring(pos1, pos2); 9 }
然后通过正则表达式获取一个列表:
1 Pattern pt = Pattern.compile(rb.getRegex()); 2 ?Matcher mt = pt.matcher(contentArea); 3 4 while (mt.find()) {
提取单笔记录
要领同提取内容部分差不久不多,如单笔记录的起始标签为<div>,结束标签相对来说也对照难确定。
获取单笔记录,并去除空格之类的无用字符:
1 String rowContent = mt.group(); 2 3 rowContent = rowContent.replaceAll(rb.getRemoveRegex(), "");
提取出标题
取出标题用的是 >.?</a>或者title=.?>,并且要去除空格和多余的字符,需要用到类似:<li>|</li>|(<img)([\s\S]?)(>)|(<div)([\s\S]?)(>)|</div>或者(<table)([\s\S]?)(>)|<tr>|(<td)([\s\S]?)(>)|</td>|</tr>|(<table)([\s\S]*?)(>)之类的。
温馨提示: 本文由Jm博客推荐,转载请保留链接: https://www.jmwww.net/file/web/32276.html

![[转]Node.js中package.json中^和~的区别](/uploads/allimg/200519/054J34453_lit.png "[转]Node.js中package.json中^和~的区别")