Flink周期性地通过分布式快照技术Checkpoints实现状态的持久化维护
标签:
Apache Flink是什么?在今世数据量激增的时代,各类业务场景都有大量的业务数据孕育产生,对付这些不停孕育产生的数据应该如何进行有效的措置惩罚惩罚,成为当下大大都公司所面临的问题。跟着雅虎对hadoop的开源,越来越多的大数据措置惩罚惩罚技术开始涌入人们的视线,例如目前对照风行的大数据措置惩罚惩罚引擎Apache Spark,根基上已经代替了MapReduce成为当前大数据措置惩罚惩罚的标准。但是跟着数据的不停增长,,新技术的不停成长,人们逐渐意识到对实时数据措置惩罚惩罚的重要性。相对付传统的数据措置惩罚惩罚模式,流式数据措置惩罚惩罚有着更高的措置惩罚惩罚效率和本钱控制能力。Flink 就是近年来在开源社区不停成长的技术中的能够同时撑持高吞吐、低延迟、高性能的漫衍式措置惩罚惩罚框架。
https://img2018.cnblogs.com/blog/1089984/201911/1089984-20191118101924177-357668057.jpg
https://img2018.cnblogs.com/blog/1089984/201911/1089984-20191118101924451-1484200707.jpg
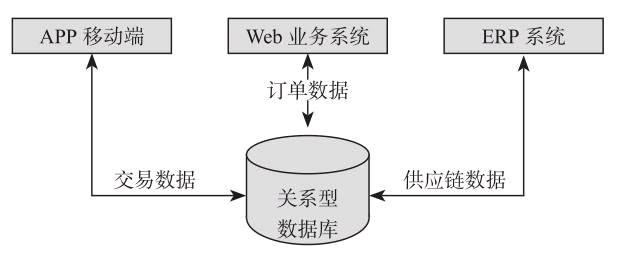
如图所示,传统的单体数据架构最大的特点等于 集中式数据存储,大大都将架构分为计算层和存储层。
单体架构的初期效率很高,但是跟着时间的推移,业务越来越多,系统逐渐变得很大,越来越难以维护和升级,数据库是独一的准确数据源,每个应用都需要访谒数据库来获取对应的数据,如果数据库产生转变或者呈现问题,则将对整个业务系统孕育产生影响。
后来跟着微处事架构的呈现,企业开始给与微处事作为企业业务系统的架构体系。微处事架构的核心思想是:一个应用是由多个小的、彼此独立的微处事构成,这些处事运行在本身的进程中,开发和颁布都没有依赖。差此外处事能依据差此外业务需求,构建的差此外技术架构之上,能够聚焦在有限的业务成果。 如图
https://img2018.cnblogs.com/blog/1089984/201911/1089984-20191118101926573-867172114.jpg
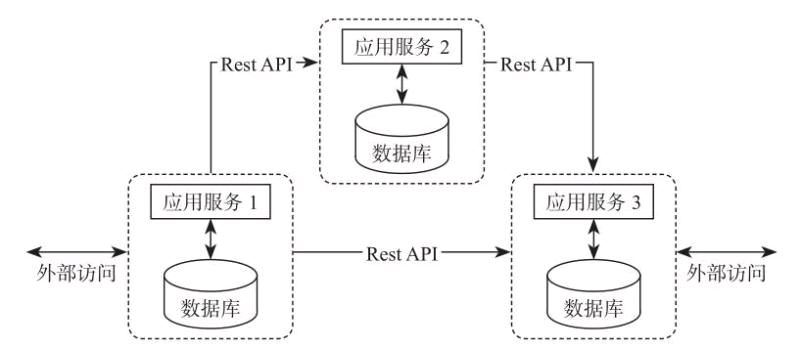
微处事架构
起初数据货仓主要还是构建在关系型数据库之上。例如Oracle、Mysql等数据库,但是跟着企业数据量的增长,关系型数据库已经无法支撑大规模数据集的存储和分析,因为越来越多的企业开始选择基于Hadoop构建企业级大数据平台。同时众多的Sql_on_hadhoop上构建差别类型的数据应用变得简单而高效。
在构建企业数据货仓的过程中,数据往往都是周期性的从业务系统中同步到大数据平台,完成一系列的ETL转换行动之后,最终形成了数据集市等应用。但是对付一些时间要求对照高的应用,例如实时报表统计,则必需有非常低的延时展示统计功效,为此业界提出了一套Lambda架构方案来措置惩罚惩罚差别类型的数据。
https://img2018.cnblogs.com/blog/1089984/201911/1089984-20191118101928298-517680567.jpg
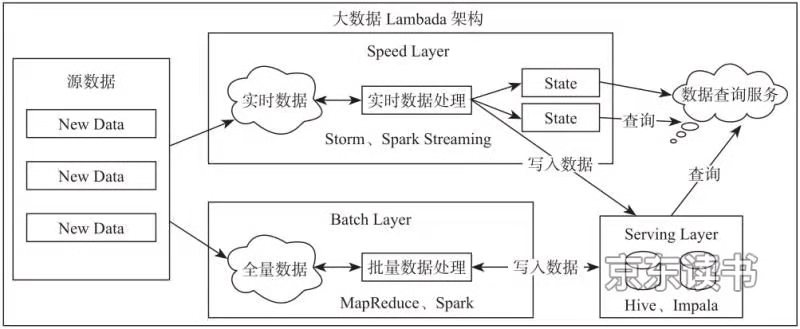
大数据lambada架构
大数据平台中包罗批量计算的Batch Layer和实时计算的Speed Layer,通过在一套平台中将批计算和流计算整合在一起,例如使用Hadoop MapReduce进行批量数据的措置惩罚惩罚,使用Apache Storm进行实时数据的措置惩罚惩罚。这种架构在必然水平上解决了差别计算类型的问题,但是带来的问题是框架太多会导致平台庞大渡过高、运维本钱高档。在一套资源打点平台中打点差别类型的计算框架使用也长短常困难的工作。
后来跟着Apache Spark的漫衍式内存措置惩罚惩罚框架的呈现,提出了将数据切分成微批的措置惩罚惩罚模式进行流式数据措置惩罚惩罚,从而能够在一套计算框架内完成批量计算和流式计算。但因为Spark自己是基于批措置惩罚惩罚模式的原因,并不能完美且高效的措置惩罚惩罚原生的数据流,因此对流式计算撑持的相对较弱,可以说Spark的呈现素质上是在必然水平上对Hadoop架构进行了必然的升级和优化。
有状态流计算架构数据孕育产生的素质,其实是一条条真实存在的事件,前面提到的差此外架构其实都是在必然水平违背了这种素质,需要通过在一按时延的情况下对业务数据进行措置惩罚惩罚,然后得到基于业务数据统计的准确功效。实际上,基于流式计算技术局限性,我们很难再数据孕育产生的过程中进行计算并直接孕育产生统计功效,因为这不只对系统有非常高的要求,还必需要满足高性能、高吞吐、低延时等众多方针。
https://img2018.cnblogs.com/blog/1089984/201911/1089984-20191118101929560-1983652334.jpg
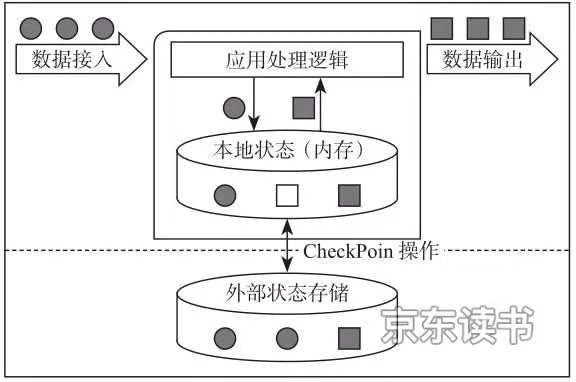
基于有状态计算的方法最大的优势是不需要将原始数据从头从外部存储中拿出来,从而进行全量计算,因为这种计算方法的价钱可能长短常高的。
温馨提示: 本文由Jm博客推荐,转载请保留链接: https://www.jmwww.net/file/web/32123.html
- 上一篇:它本质上是一个大的消息缓冲器
- 下一篇: 注释:请在此列表的末端始终定义一种普通的光标

![[转]Node.js中package.json中^和~的区别](/uploads/allimg/200519/054J34453_lit.png "[转]Node.js中package.json中^和~的区别")