cfg):layers = []previous_channel = in_channels #上一层的输出的chann
AlexNet在Lenet的根本上增加了几个卷积层,转变了卷积核巨细,每一层输出通道数目等,并且取得了很好的效果.但是并没有提出一个简单有效的思路.
VGG做到了这一点,提出了可以通过反复使?简单的根本块来构建深度学习模型的思路.
论文地点:https://arxiv.org/abs/1409.1556
vgg的布局如下所示:
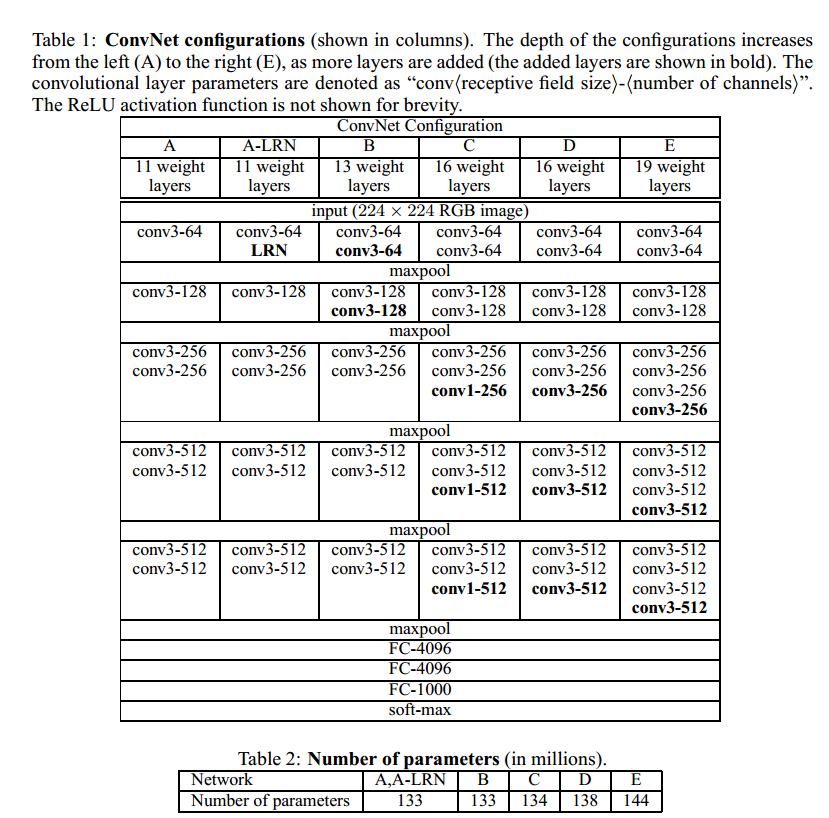
上图给出了差别层数的vgg的布局.也就是常说的vgg16,vgg19等等. VGG BLOCK
vgg的设计思路是,通过不停堆叠3x3的卷积核,不停加深模型深度.vgg net证明了加深模型深度对提高模型的学习能力是一个很有效的手段.
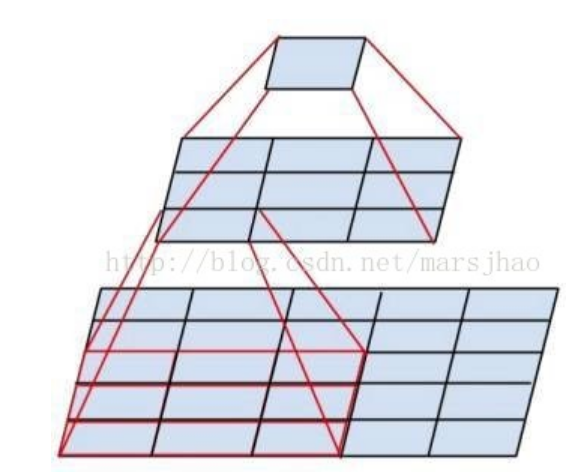
看上图就能发明,持续的2个3x3卷积,感应熏染野和一个5x5卷积是一样的,但是前者有两次非线性调动,后者只有一次!,这就是持续堆叠小卷积核能提高
模型特征学习的关键.别的,2个3x3的参数数量也比一个5x5少.(2x3x3 < 5x5)
vgg的根本构成模块,每一个卷积层都由n个3x3卷积后面接2x2的最大池化.池化层的步幅为2.从而卷积层卷积后,宽高不乱,池化后,宽高减半.
我们可以有以下代码:
cfgs界说了差此外vgg模型的布局,好比‘A‘代表vgg11. 数字代表卷积后的channel数. ‘M‘代表Maxpool
我们可以给出模型界说
class VGG(nn.Module): def __init__(self,input_channels,cfg,num_classes=10, init_weights=True): super(VGG, self).__init__() self.conv = make_layers(input_channels,cfg) # torch.Size([1, 512, 7, 7]) self.fc = nn.Sequential( nn.Linear(512*7*7,4096), nn.ReLU(), nn.Linear(4096,4096), nn.ReLU(), nn.Linear(4096,num_classes) ) def forward(self, img): feature = self.conv(img) output = self.fc(feature.view(img.shape[0], -1)) return output卷积层的输出可由以下测试代码得出
# conv = make_layers(1,cfgs['A']) # X = torch.randn((1,1,224,224)) # out = conv(X) # #print(out.shape) 加载数据 batch_size,num_workers=4,4 train_iter,test_iter = learntorch_utils.load_data(batch_size,num_workers,resize=224)这里batch_size调到8我的显存就不够了...
界说模型 net = VGG(1,cfgs['A']).cuda() 界说损掉函数 loss = nn.CrossEntropyLoss() 界说优化器 opt = torch.optim.Adam(net.parameters(),lr=0.001) 界说评估函数 def test(): acc_sum = 0 batch = 0 for X,y in test_iter: X,y = X.cuda(),y.cuda() y_hat = net(X) acc_sum += (y_hat.argmax(dim=1) == y).float().sum().item() batch += 1 #print('acc_sum %d,batch %d' % (acc_sum,batch)) return 1.0*acc_sum/(batch*batch_size) 训练 num_epochs = 3 def train(): for epoch in range(num_epochs): train_l_sum,batch,acc_sum = 0,0,0 start = time.time() for X,y in train_iter: # start_batch_begin = time.time() X,y = X.cuda(),y.cuda() y_hat = net(X) acc_sum += (y_hat.argmax(dim=1) == y).float().sum().item() l = loss(y_hat,y) opt.zero_grad() l.backward() opt.step() train_l_sum += l.item() batch += 1 mean_loss = train_l_sum/(batch*batch_size) #计算平均到每张图片的loss start_batch_end = time.time() time_batch = start_batch_end - start print('epoch %d,batch %d,train_loss %.3f,time %.3f' % (epoch,batch,mean_loss,time_batch)) print('***************************************') mean_loss = train_l_sum/(batch*batch_size) #计算平均到每张图片的loss train_acc = acc_sum/(batch*batch_size) #计算训练准确率 test_acc = test() #计算测试准确率 end = time.time() time_per_epoch = end - start print('epoch %d,train_loss %f,train_acc %f,test_acc %f,time %f' % (epoch + 1,mean_loss,train_acc,test_acc,time_per_epoch)) train()4G的GTX 1050显卡,训练一个epoch概略一个多小时.
完整代码:https://github.com/sdu2011/learn_pytorch
从新学pytorch(十六):VGG NET
,温馨提示: 本文由Jm博客推荐,转载请保留链接: https://www.jmwww.net/file/web/31843.html

![[转]Node.js中package.json中^和~的区别](/uploads/allimg/200519/054J34453_lit.png "[转]Node.js中package.json中^和~的区别")