HTTP 长链接
一、什么是长连接
HTTP1.1规定了默认连结长连接(HTTP persistent connection ,也有翻译为长期连接),数据传输完成了连结TCP连接不停开(不发RST包、不四次握手),期待在同域名下继续用这个通道传输数据;相反的就是短连接。
HTTP首部的Connection: Keep-alive是HTTP1.0浏览器和处事器的尝试性扩展,当前的HTTP1.1 RFC2616文档没有对它做说明,因为它所需要的成果已经默认开启,无须带着它,但是实践中可以发明,浏览器的报文请求城市带上它。如果HTTP1.1版本的HTTP请求报文不但愿使用长连接,则要在HTTP请求报文首部加上Connection: close。《HTTP权威指南》提到,有部分陈腐的HTTP1.0 代办代理不理解Keep-alive,而导致长连接掉效:客户端-->代办代理-->处事端,客户端带有Keep-alive,而代办代理不认识,于是将报文原封不动转给了处事端,处事端响应了Keep-alive,也被代办代理转发给了客户端,于是连结了“客户端-->代办代理”连接和“代办代理-->处事端”连接不封锁,但是,当客户端第发送第二次请求时,代办代理会认为当前连接不会有请求了,于是忽略了它,长连接掉效。书上也介绍了解决方案:当发明HTTP版本为1.0时,就忽略Keep-alive,客户端就知道当前不该使用长连接。其实,在实际使用中不需要考虑这么多,很多时候代办代理是我们本身控制的,如Nginx代办代理,代办代理处事器有长连接措置惩罚惩罚逻辑,处事端无需做patch措置惩罚惩罚,常见的是客户端跟Nginx代办代理处事器使用HTTP1.1协议&长连接,而Nginx代办代理处事器跟后端处事器使用HTTP1.0协议&短连接。
在实际使用中,HTTP头部有了Keep-Alive这个值并不代表必然会使用长连接,客户端和处事器端都可以无视这个值,也就是不按标准来,譬如我本身写的HTTP客户端多线程去下载文件,就可以不遵循这个标准,并发的或者持续的多次GET请求,都分隔在多个TCP通道中,每一条TCP通道,只有一次GET,GET完之后,当即有TCP封锁的四次握手,这样写代码更简单,这时候虽然HTTP头有Connection: Keep-alive,但不能说是长连接。正常情况下客户端浏览器、web处事端都有实现这个标准,因为它们的文件又小又多,连结长连接减少从头开TCP连接的开销很有价值。
以前使用libcurl做的上传/下载,就是短连接,抓包可以看到:1、每一条TCP通道只有一个POST;2、在数据传输完毕可以看到四次握手包。只要不挪用curl_easy_cleanup,curl的handle就可能一直有效,可复用。这里说可能,因为连接是双方的,如果处事器那边关失了,那么我客户端这边保存着也不能实现长连接。
如果是使用windows的WinHTTP库,则在POST/GET数据的时候,虽然我封锁了句柄,但这时候TCP连接并不会当即封锁,而是等一小会儿,这时候是WinHTTP库底层撑持了跟Keep-alive所需要的成果:即便没有Keep-alive,WinHTTP库也可能会加上这种TCP通道复用的成果,而其它的网络库像libcurl则不会这么做。以前不雅察看过WinHTTP库不会及时断开TCP连接。
二、长连接的过期时间
客户真个长连接不成能无限期的拿着,会有一个超不时间,处事器有时候会报告客户端超不时间,譬如:
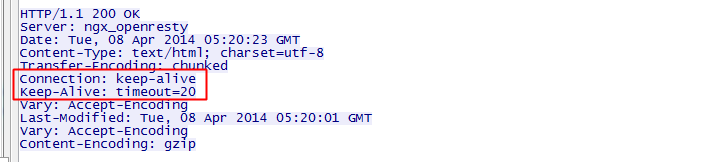
上图中的Keep-Alive: timeout=20,暗示这个TCP通道可以连结20秒。此外还可能有max=XXX,暗示这个长连接最多接收XXX次请求就断开。对付客户端来说,如果处事器没有报告客户端超不时间也不妨,处事端可能主动倡议四次握手断开TCP连接,客户端能够知道该TCP连接已经无效;此外TCP还有心跳包来检测当前连接是否还活着,要领很多,制止浪费资源。
三、长连接的数据传输完成识别
使用长连接之后,客户端、处事端怎么知道本次传输结束呢?两部分:1是判断传输数据是否到达了Content-Length指示的巨细;2动态生成的文件没有Content-Length,它是分块传输(chunked),这时候就要按照chunked编码来判断,chunked编码的数据在最后有一个空chunked块,表白本次传输数据结束。更细节的介绍可以看这篇文章。
四、并发连接数的数量限制
在web开发中需要存眷浏览器并发连接的数量,说,客户端与处事器最多就连上两通道,但处事器、小我私家客户端要不要这么做就随人意了,有些处事器就限制同时只能有1个TCP连接,导致客户真个多线程下载(客户端跟处事器连上多条TCP通道同时拉取数据)阐扬不了威力,有些处事器则没有限制。浏览器客户端就对照端方,知乎这里有分析,限制了同域名下能启动若干个并发的TCP连接去下载资源。并发数量的限制也跟长连接有关联,打开一个网页,很多个资源的下载可能就只被放到了少数的几条TCP连接里,这就是TCP通道复用(长连接)。如果并发连接数少,意味着网页上所有资源下载完需要更长的时间(用户觉得页面打开卡了);并发数多了,处事器可能会孕育产生更高的资源消耗峰值。浏览器只对同域名下的并发连接做了限制,也就意味着,web开发者可以把资源放到差别域名下,同时也把这些资源放到差此外机器上,这样就完美解决了。
五、容易混淆的观点——TCP的keep alive和HTTP的Keep-alive
TCP的keep alive是查抄当前TCP连接是否活着;HTTP的Keep-alive是要让一个TCP连接活久点。它们是差别条理的观点。
TCP keep alive的表示:
温馨提示: 本文由Jm博客推荐,转载请保留链接: https://www.jmwww.net/file/web/31503.html

![[转]Node.js中package.json中^和~的区别](/uploads/allimg/200519/054J34453_lit.png "[转]Node.js中package.json中^和~的区别")