[论文理解] Why do deep convolutional networks generalize so poor
标签:
Why do deep convolutional networks generalize so poorly to small image transformations? IntroCNN的设计初衷是为了使得模型具有微小平移、旋转不乱性,而实际上本文通过尝试验证了此刻对照风行的神经网络都已经丧掉了这样的能力,甚至图像只程度移动一个像素,预测的功效都将会产生很大的变革。之所以如此,作者认为CNN的下采样背离了隆奎斯特采样定理,就连augmentation也并不能缓解微小变革不乱性的丧掉。
Ignoring the Sampling Theorem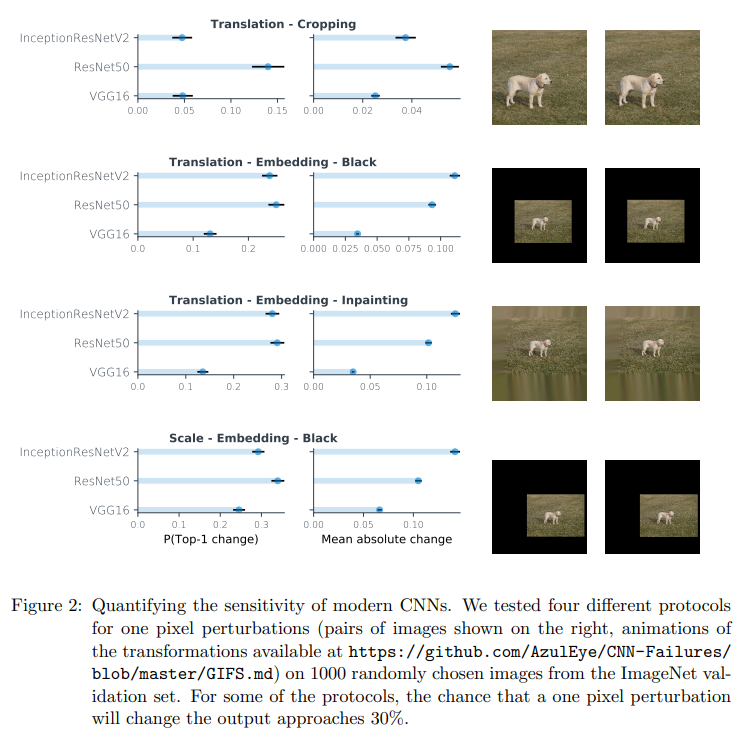
随机crop一张图然后resize,平移一个像素
原图rescale黑色填充配景,平移一个像素
原图rescale下方插值,平移一个像素
原图rescale,rescale相差一个像素值
功效如图,对人而言是看不出来什么区另外,但是网络的预测功效却明显差别。
仅仅这么一个微小变革,使得网络的输出产生这么大的变革,这显然是很不同理的,因此作者认为有下面的解释。
作者认为之所以CNN丧掉了平移不乱性是因为此刻CNN的设计忽略了采样定理,也就是奈奎斯特采样定理。作者认为,CNN中的下采样操纵,如stride 2 conv和pooling,由于采样频率没满足大于即是两倍的最高频,所以会导致微小形变不乱性的丧掉。
如何理解?

上图我做了三个尝试,分袂是原图、pooling后的图、conv2d(stride=4)后的图,下面是对应的频谱图。可以看出来,pooling、conv下采样层都是保存高频部分,,抛弃低频部分。
可见,pooling层和conv层所做的下采样都是保存高频,抛弃低频身分。因此信号的频率都是高频,而采样频率是和stride相关的,可以理解为每隔几多像素采样一次,因此如果stride太大,采样频率就会过小,这样就不满足采样定理了。
import cv2 import numpy as np import matplotlib.pyplot as plt import skimage.measure import torch import torch.nn as nn import torch.nn.functional as F class FFT(object): def __init__(self): pass def __call__(self,x): f = np.fft.fft2(x) fshift = np.fft.fftshift(f) s1 = np.log(np.abs(fshift)) return s1 @staticmethod def pooling(feature_map,kernel_size= 2): inpt = torch.tensor(feature_map[np.newaxis,np.newaxis,:,:],dtype = torch.float32) out = F.max_pool2d(inpt,kernel_size = kernel_size) return out.numpy()[0,0,:,:] #return skimage.measure.block_reduce(feature_map, (kernel_size,kernel_size), np.max) @staticmethod def conv2d(feature_map,kernel_size= 2,stride = 1): inpt = torch.tensor(feature_map[np.newaxis,np.newaxis,:,:],dtype = torch.float32) kernel = torch.ones((1,1,kernel_size,kernel_size)) / kernel_size out = F.conv2d(inpt,weight = kernel,stride = stride) return out.numpy()[0,0,:,:] if __name__ == "__main__": fft = FFT() img = cv2.imread('/home/xueaoru/图片/test002.jpg', 0) img2 = fft.pooling(img,4) img3 = fft.conv2d(img,kernel_size = 5,stride = 4) s1 = fft(img) s2 = fft(img2) s3 = fft(img3) plt.subplot(231) plt.imshow(img, 'gray') plt.title('original') plt.subplot(232) plt.imshow(img2, 'gray') plt.title('original2') plt.subplot(233) plt.imshow(img3, 'gray') plt.title('original3') plt.subplot(234) plt.imshow(s1,'gray') plt.title('center1') plt.subplot(235) plt.imshow(s2,'gray') plt.title('center2') plt.subplot(236) plt.imshow(s3,'gray') plt.title('center3') plt.show()
别的,作者还说明了一件事:
网络越深,微小形变不乱性丧掉的越严重。上图可以看出vgg16对照浅,还看不出什么变革,但是resnet50已经丧掉很多了,densenet201也是一样。
Why don‘t modern CNNs learn to be invariant from data?我们训练之前一般会做很多image augmentation的,但是呢,为什么image augmentation也没能缓解平移不乱性的丧掉呢?
一个简单的回答就是网络学习到一种简单的判别函数,使得网络对训练集的图片的调动具有微小形变不乱性,而对付测试集或者说没见过的数据的微小形变不具有不乱性。这称为dataset bias。
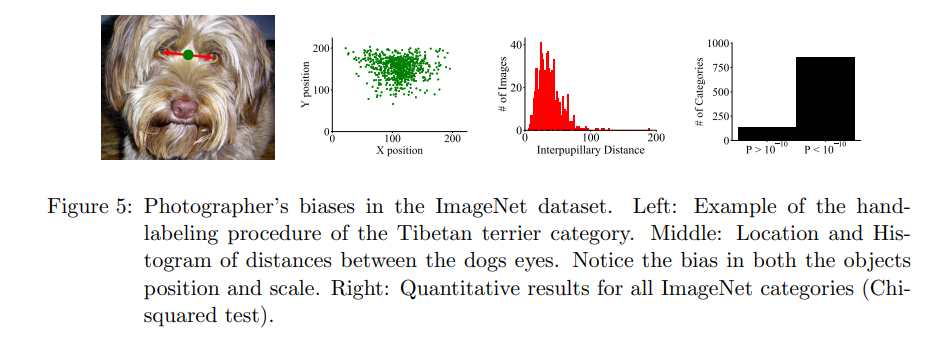
上图是imagenet上训练集里狗的眼睛距离的统计功效,也就是说,一般情况下狗的眼睛必定在这个range内,网络可以work,然是测试数据的眼睛距离如果不在这个range内的话,网络也许就不work了,因此要求网络学习到这个range之外的数据是很难的,虽然image augmentation有所辅佐,但其实很难泛化到所有情况,出格是测试集和训练集不是同一漫衍的时候。
Possible Solutions将下采样替换为:stride 1 maxpooling + stride 2 conv.也就是采样之前先blur,但是对付大数据效果甚微。
data augmentation:多增加特别的augmentation。
减少二次采样操纵:二次采样会导致可能不满足采样定律,所以减少二次采样可以连结不乱性。
[论文理解] Why do deep convolutional networks generalize so poorly to small image transformations?
温馨提示: 本文由Jm博客推荐,转载请保留链接: https://www.jmwww.net/file/web/31155.html
- 上一篇:版本已经升级到1.17了
- 下一篇:angularjs脏查抄

![[转]Node.js中package.json中^和~的区别](/uploads/allimg/200519/054J34453_lit.png "[转]Node.js中package.json中^和~的区别")