(5)spooling directory source #p#分页标题#e# spooling directory
记录一下日志收罗框架flume的相关内容,flume是由Cloudera开发,后面孝敬给了Apache,是一个漫衍式的、不变的,用于日志收罗、汇聚和传输的系统,此刻用的一般是1.x版本,老版本的因为用得少暂时不考虑。

包孕agent和event。
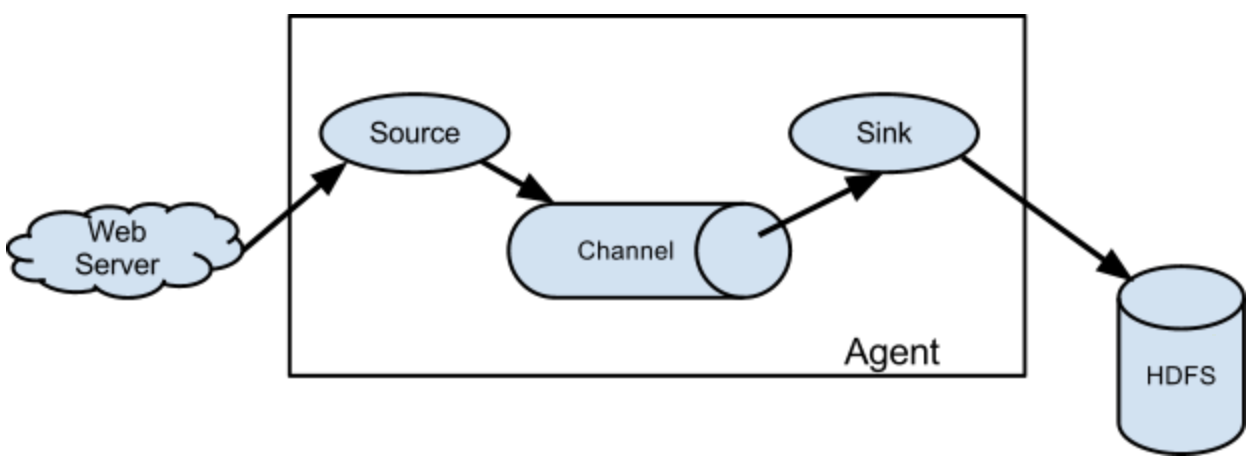
Agent以下是数据流模型图,source+channel+sink构成一个agent,一个agent完成从数据源获取数据,到写出数据到目的地,它素质上是一个java进程。
(1)source,source不是数据收罗的起源地,是用于对接数据源的,它是从起源地如web server收罗源数据,或者从上一个agent sink的功效收罗数据,可以理解为水管。
(2)channel,是一个数据姑且存储区域,当数据在sink被消费后,才从channel删除,这样可以保证数据传输的安适和可靠性,可以理解成一个蓄水水箱。
(3)sink,将数据发给目的地,可以是hdfs,也可以是下一个agent收罗数据的起源地等,可以理解为水轮头。
Event是flume中传输的根基单位,一条动静会被封装成event东西,它素质上是一个json字符串,携带headers、body和动静体,动静是放在body里的,ETL写自界说拦截器时需要跟这两个打交道。
Flume庞大流动上图是一个单级流动,除了单级流动flume还撑持多级流动、扇入流动和扇出流动。
多级流动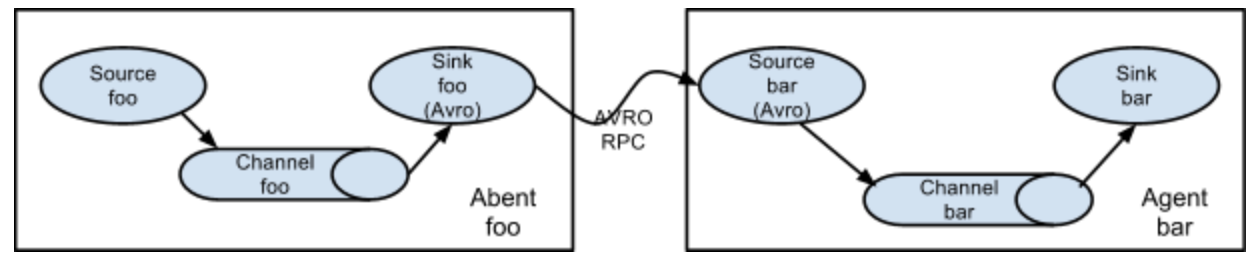
如图是两个agent串联的多级流动,上一级的sink和下一级的source均是avro类型,上一级配置sink指向下一级souce的hostname和port。
扇入流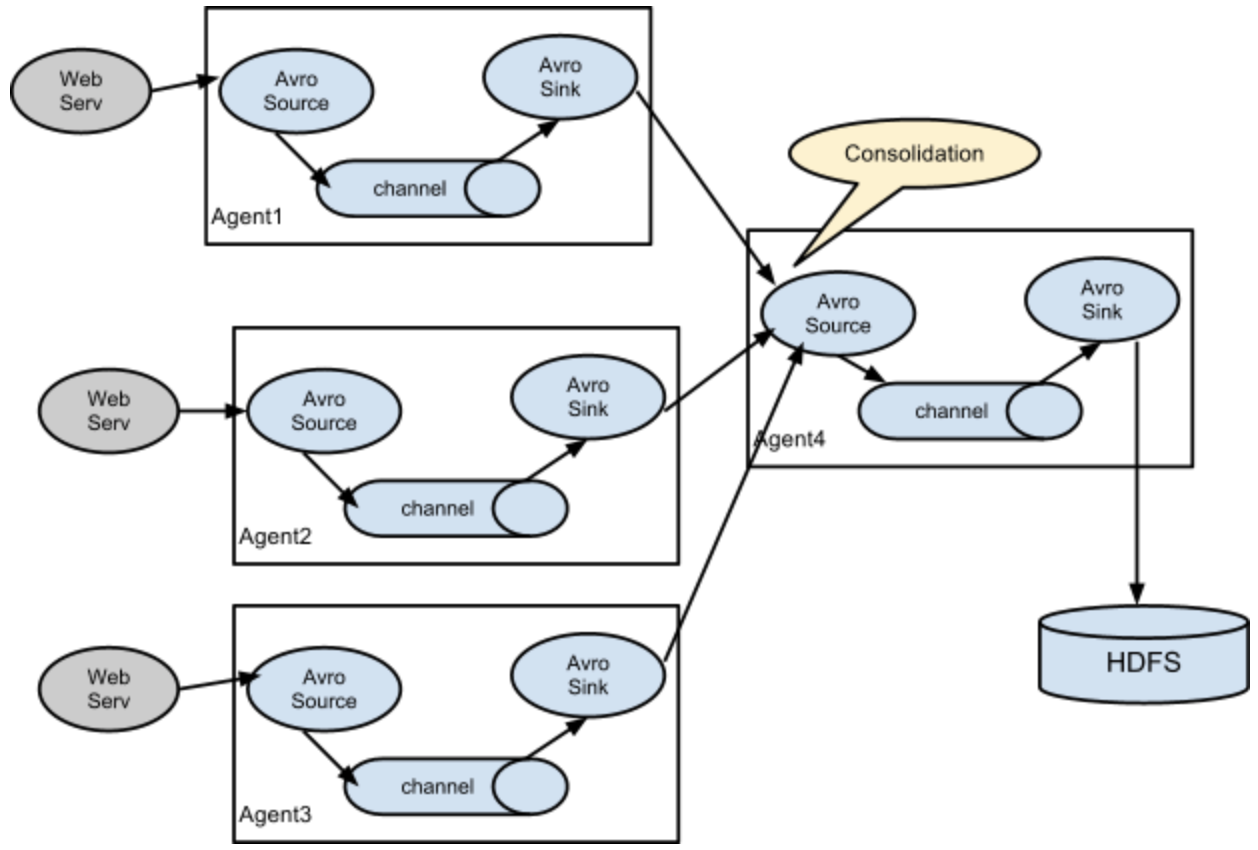
如图是扇入类型,官方文档有介绍一种应用场景,即几百个web处事器出产的日志,都汇入到十几个从属于存储子系统上的agent上。上图也可以配置完成,在agent1、agent2和agent3的sink中,指向agent4中source的hostname和port,最后agent4颠末一个channel,将event统一写出到hdfs。
扇出流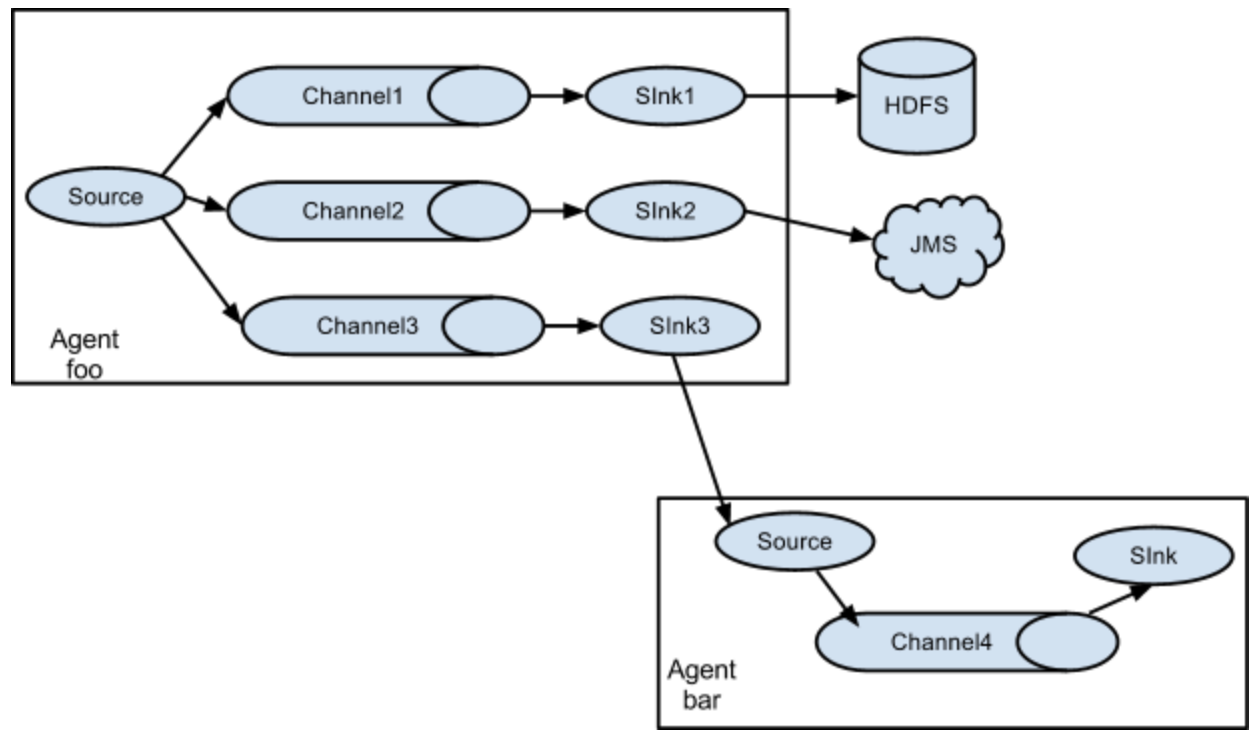
如图是扇出类型,可以复制或多路输出,如果是复制则一个event将进入到三个channel,如果是多路输出,则event只会进入到切合条件的channel。这些都是通过agent中来配置的。
各大组件配置使用三大组件包孕source、channel和sink,每个组件按照业务场景的差别,会有多种type供选择,如何配置它们可以参考官方文档,注意版本,新版本会添加一些成果,如type为taildir的source,就是1.7更新后添加,1.7版本也是出产环境对照不变的版本并且和1.x的老版本兼容。
接下来就是写配置文件了,差此外场景配置文件大同小异,主体布局是一样的,都是配置三大组件,并连接source和channel,channel和sink。
sourcesouce按照type的差别有多种选择,包孕netcat、avro、thrift、exec、jms、spooling、directory、sequence generator、syslog、http、legacy、自界说等。
(1)netcat source
netcat用于监听一个指定的端口的tcp请求数据,配置如下。
# 配置Agent,需要给Agent指定一个名字,取名a1 # 需要绑定Source,并给Source取名 a1.sources=s1 # 绑定channel,并且给Channel取名 a1.channels=c1 # 绑定Sink,并且给Sink取名 a1.sinks=k1 # 配置netcat source a1.sources.s1.type=netcat a1.sources.s1.bind=hadoop01 a1.sources.s1.port=8090 # 配置Channel 暂时用memory a1.channels.c1.type=memory # 内存空间有限,限定最大10000条event a1.channels.c1.capacity=10000 # 批次sink的数量是100条 a1.channels.c1.transactionCapacity=100 # 配置sink,日志的形式打印 a1.sinks.k1.type=logger # 将Source和Channel进行绑定 a1.sources.s1.channels=c1 # 将Channel和Sink进行绑定 a1.sinks.k1.channel=c1
配置好后,需启动agent,并加载上面的配置文件,
# 配置文件写在data目录下,启动flume
# agent用于启动一个agent a1
# -c 用于加载原生配置
# -f 用户加载指定配置
# info,console代表控制台打印日志
[[email protected] /home/software/apache-flume-1.6.0-bin/data]# ../bin/flume-ng agent -n a1 -c ../conf/ -f ./basic.conf -Dflume.root.logger=info,console
...略
# 此外开启一个窗口,通过nc访谒
[[email protected] ~]# nc hadoop01 8090
hello buddy
OK
# 原窗口监听到nc
2020-01-21 10:03:38,709 (lifecycleSupervisor-1-3) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:164)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/192.168.200.140:8090]
# 接收到日志信息,可以看出event由headers、body和动静体构成
2020-01-21 10:05:04,970 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 68 65 6C 6C 6F 20 62 75 64 64 79
hello buddy }
(2)avro source
avro source接收的是avro序列化后的数据,然后反序列化后继续传输, 可以实现以上三种庞大流动。接下来使用avro client发送数据,测试接收。
温馨提示: 本文由Jm博客推荐,转载请保留链接: https://www.jmwww.net/file/web/31082.html

![[转]Node.js中package.json中^和~的区别](/uploads/allimg/200519/054J34453_lit.png "[转]Node.js中package.json中^和~的区别")