Auto-Encoders与传统FNN或者CNN的区别在于它的输入维度与输出维度相同
无监督学习和监督学习是机器学习的两个标的目的,监督学习主要适用于已经标注好的数据集(如mnist分类问题),,无监督学习则是但愿计算机完成庞大的标注任务,简单的解释就是——教机器本身学习,它常见的应用场景有:从复杂的样本调集中选出一些具有代表性的加以标注用于分类器的训练、将所有样本自动分为差此外类别,再由人类对这些类别进行标注、在无类别信息的情况下,寻找好的特征。
2.Auto-Encoders
Auto-Encoders一大重要应用就是生成数据集,新手了解VAE一般都从生成mnist数据集开始,对付生成mnist的一个网络模型,Auto-Encoders与传统FNN或者CNN的区别在于它的输入维度与输出维度不异,且中间有一个neck层用于降维或升维,颠末这样一个操纵可以连结输入数据的语义相关性。
下图是只有一个包罗两个神经元的隐藏层以及包罗3个神经元的输出层的自编码器,输出是在设法重建输入,损掉函数是重建损掉
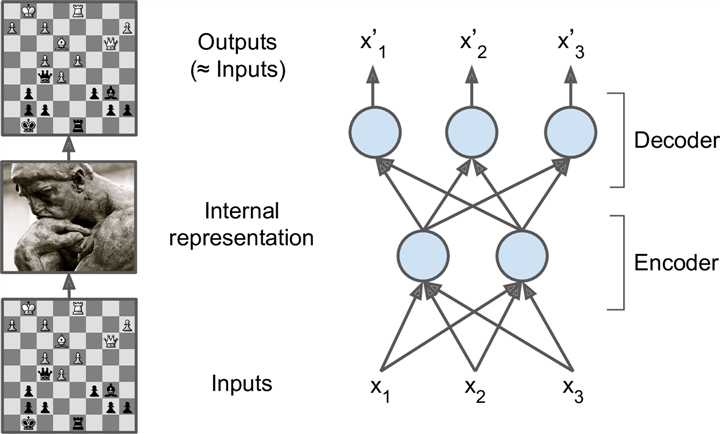
在Auto-Encoders的训练过程中,最常用的Loss function有均方误差和交叉熵,此中,交叉熵损掉函数越发适用于二进制的输入数据。
3.Auto-Encoders的变种
经常拿来和Auto-Encoder对照的一个数据降维的要领叫PCA
PCA的道理请见以下链接:https://blog.csdn.net/program_developer/article/details/80632779
Auto-Encoders的一个变种叫Denoising AutoEncoders,它是为了防备模型对像素值的纯挚记忆孕育产生的,通过插手一些噪声让网络模型在混乱的数据中发明它们真实的语义特征;还有一个变种叫做Dropout AutoEncoders,和监督学习神经网络中的dropout层原理不异,通过阻止部分神经元的激活来防备网络过拟合(可能会记住一些噪声特征,而无法提取真实的特征)
Adversarial AutoEncoders是对照有名的一个,在自编码过程中,一个对照常见的问题就是生成的数据总是方向于某一标的目的漫衍,而不切合我们平时接触的任何一种漫衍(均匀漫衍、正太漫衍、高斯漫衍等),为了解决这个问题,adversarial autoencoders通过插手一个“分辩器”来对数据进行筛选,从而保证网络输出数据的质量。
Auto-Encoder(自编码器)道理
温馨提示: 本文由Jm博客推荐,转载请保留链接: https://www.jmwww.net/file/web/30413.html

![[转]Node.js中package.json中^和~的区别](/uploads/allimg/200519/054J34453_lit.png "[转]Node.js中package.json中^和~的区别")