color= ‘ #5d7092 ‘
爽性用django+pyecharts实现疫情数据可视化web页面:
要爬的数据来自丁香园、搜狗及百度的疫情实时动态展示页
先看看劳动成就:
导航栏:

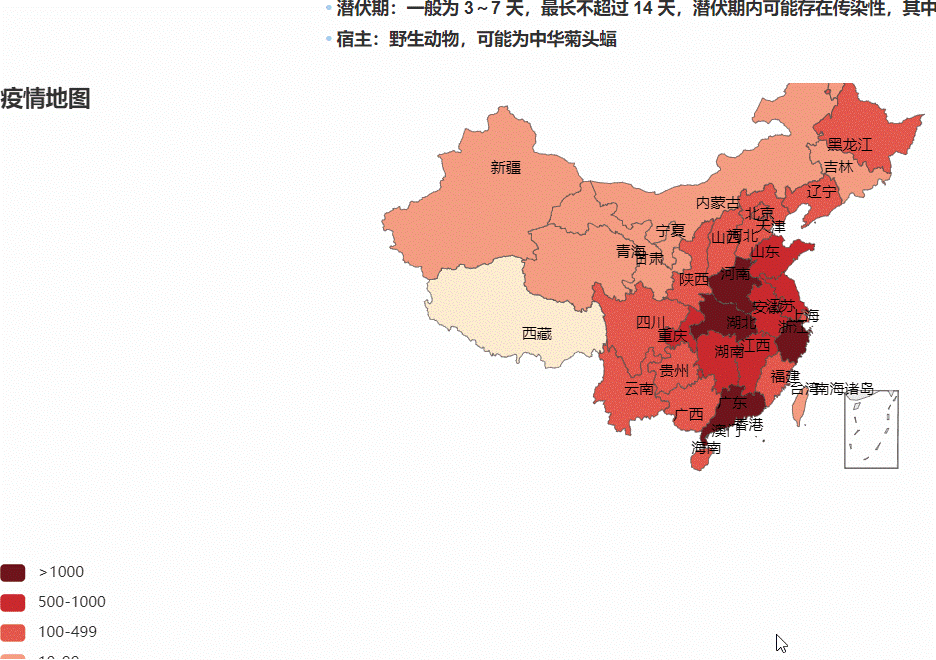
疫情地舆热力图:
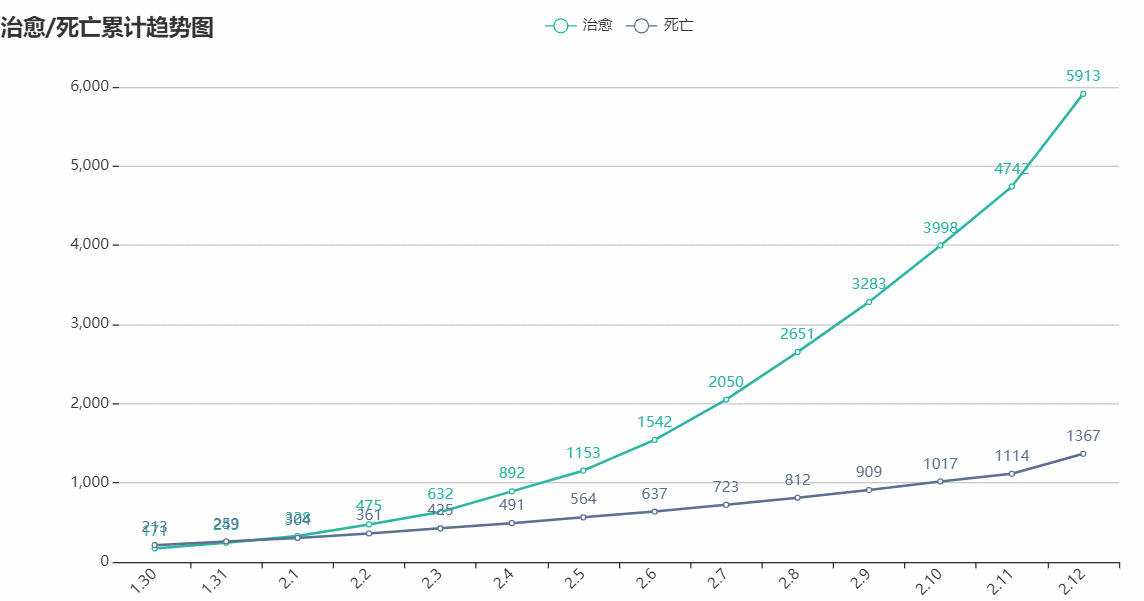
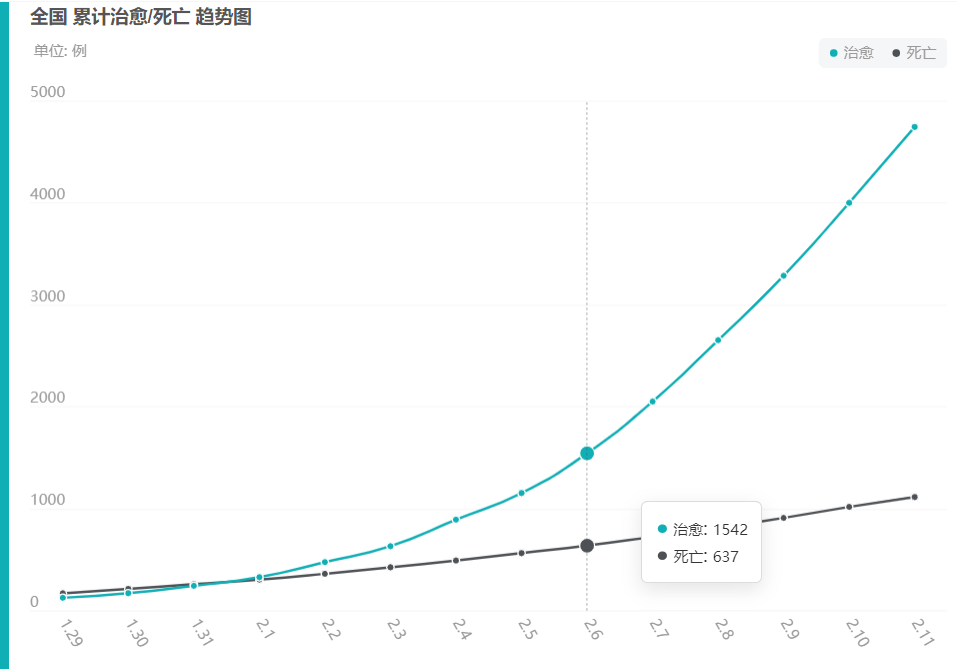
治愈/死亡折线图
舆论词云:

丁香园要爬的数据,这些数据用在阿谁地舆热力图上:
丁香园疫情实时动态(超链接)
百度要爬的数据,历史数据,用在治愈/死亡折线图上:
百度疫情实时动态
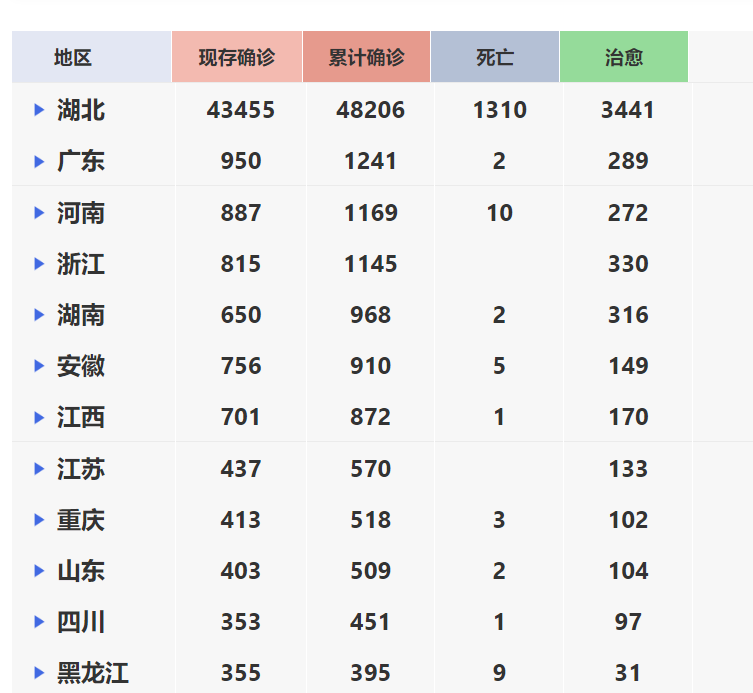
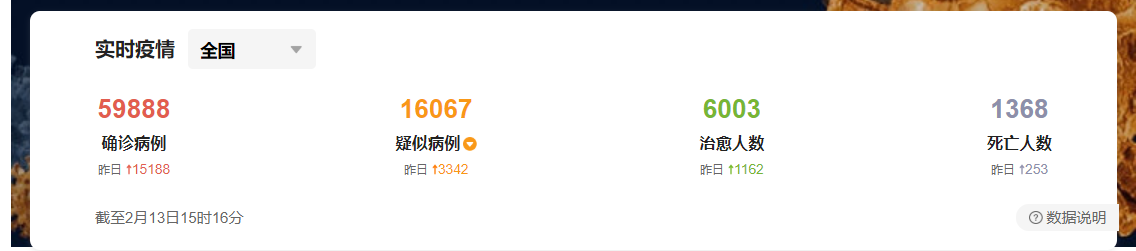
搜狗要爬的数据,用在导航栏那几个统计的总数:
搜狗疫情实时动态
还有这里,用于获取媒体的文章。制作词云~
搜狗
emmm...
正文:
爬虫:
爬这些数据其实很简单,需要的数据都在html源码里,直接用requests请求链接后用re匹配就行,而且这些网站甚至都不用伪造请求头来访谒。。。
爬虫代码:
import requests import json import re import time from pymongo import MongoClient def insert_item(item, type_): ‘‘‘ 插入数据到mongodb,item为要插入的数据,type_用来选择collection ‘‘‘ databaseIp=‘127.0.0.1‘ databasePort=27017 client = MongoClient(databaseIp, databasePort) mongodbName = ‘dingxiang‘ db = client[mongodbName] if type_ == ‘dxy_map‘: # 更新插入 db.dxy_map.update({‘id‘: item[‘provinceName‘]}, {‘$set‘: item}, upsert=True) elif type_ == ‘sogou‘: # 直接插入 db.sogou.insert_one(item) else: # 更新插入 db.baidu_line.update({},{‘$set‘: item}, upsert=True) print(item,‘插入告成‘) client.close() def dxy_spider(): ‘‘‘ 丁香园爬取,获取各省份简直诊数,用来做地舆热力图 ‘‘‘ url = ‘https://ncov.dxy.cn/ncovh5/view/pneumonia‘ r = requests.get(url) r.encoding = ‘utf-8‘ res = re.findall(‘tryTypeService1 =(.*?)}catch‘, r.text, re.S) if res: # 获取数据的改削时间 time_result = json.loads(res[0]) res = re.findall(‘getAreaStat =(.*?)}catch‘, r.text, re.S) if res: # 获取省份确诊人数数据 all_result = json.loads(res[0]) for times in time_result: for item in all_result: if times[‘provinceName‘] == item[‘provinceName‘]: # 因为省份确诊人数的部分没有时间,这里将时间整合进去 item[‘createTime‘] = times[‘createTime‘] item[‘modifyTime‘] = times[‘modifyTime‘] insert_item(item,‘dxy_map‘) def sogou_spider(): ‘‘‘ 搜狗爬虫,获取所有确诊数、治愈数等,用在导航栏直接显示 ‘‘‘ url = ‘‘ r = requests.get(url=url) sum_res = re.findall(‘"domesticStats":({"tim.*?}})‘,r.text) if sum_res: sum_result = json.loads(sum_res[0]) # 增加一个爬取时间字段 sum_result[‘crawl_time‘] = int(time.time()) insert_item(sum_result,‘sogou‘) def baidu_spider(): ‘‘‘ 百度爬虫,爬取历史数据,用来画折线图 ‘‘‘ url = ‘https://voice.baidu.com/act/newpneumonia/newpneumonia‘ r = requests.get(url=url) res = re.findall(‘"degree":"3408"}],"trend":(.*?]}]})‘,r.text,re.S) data = json.loads(res[0]) insert_item(data,‘baidu_line‘) if __name__ == ‘__main__‘: dxy_spider() sogou_spider() baidu_spider()
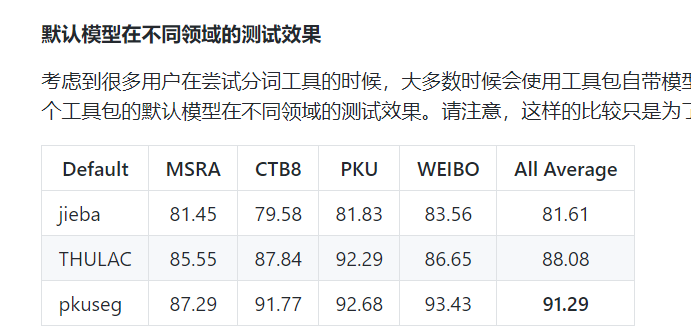
词云的数据筹备则麻烦一点,中文分词可是个麻烦事...
所以选了个精度还不错的pkuseg(pkuseg官方测试~)
代码:
温馨提示: 本文由Jm博客推荐,转载请保留链接: https://www.jmwww.net/file/web/30163.html

![[转]Node.js中package.json中^和~的区别](/uploads/allimg/200519/054J34453_lit.png "[转]Node.js中package.json中^和~的区别")