chukwa的 agent 采用了所谓的 watchdog 机制
标签:
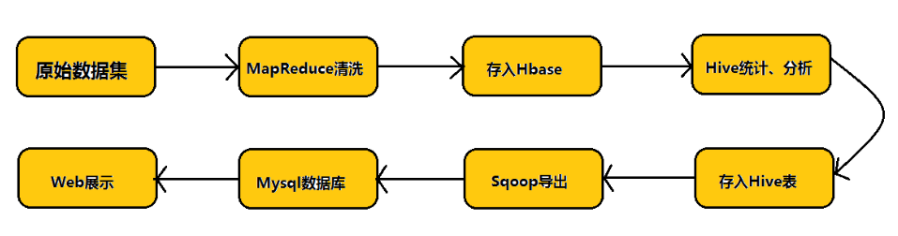
Sqoop 简介Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的通报,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
特征
Sqoop是一个用来将Hadoop和关系型数据库中的数据彼此转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
对付某些NoSQL数据库它也供给了连接器。Sqoop,类似于其他ETL工具,使用元数据模型来判断数据类型并在数据从数据源转移到Hadoop时确保类型安适的数据措置惩罚惩罚。Sqoop专为大数据批量传输设计,能够支解数据集并创建Hadoop任务来措置惩罚惩罚每个区块。
Sqoop:SQL-to-Hadoop
连接传统关系型数据库和Hadoop的桥梁 把关系型数据库的数据导入到 Hadoop 系统 ( 如 HDFS、HBase 和 Hive) 中; 把数据从 Hadoop 系统里抽取并导出到关系型数据库里
操作MapReduce,批措置惩罚惩罚方法进行数据传输
Sqoop的优势高效、可控的操作资源,任务并行度、超不时间等
数据类型映射与转换可自动进行,用户也可自界说
撑持多种数据库(MySQL、Oracle、PostgreSQL)
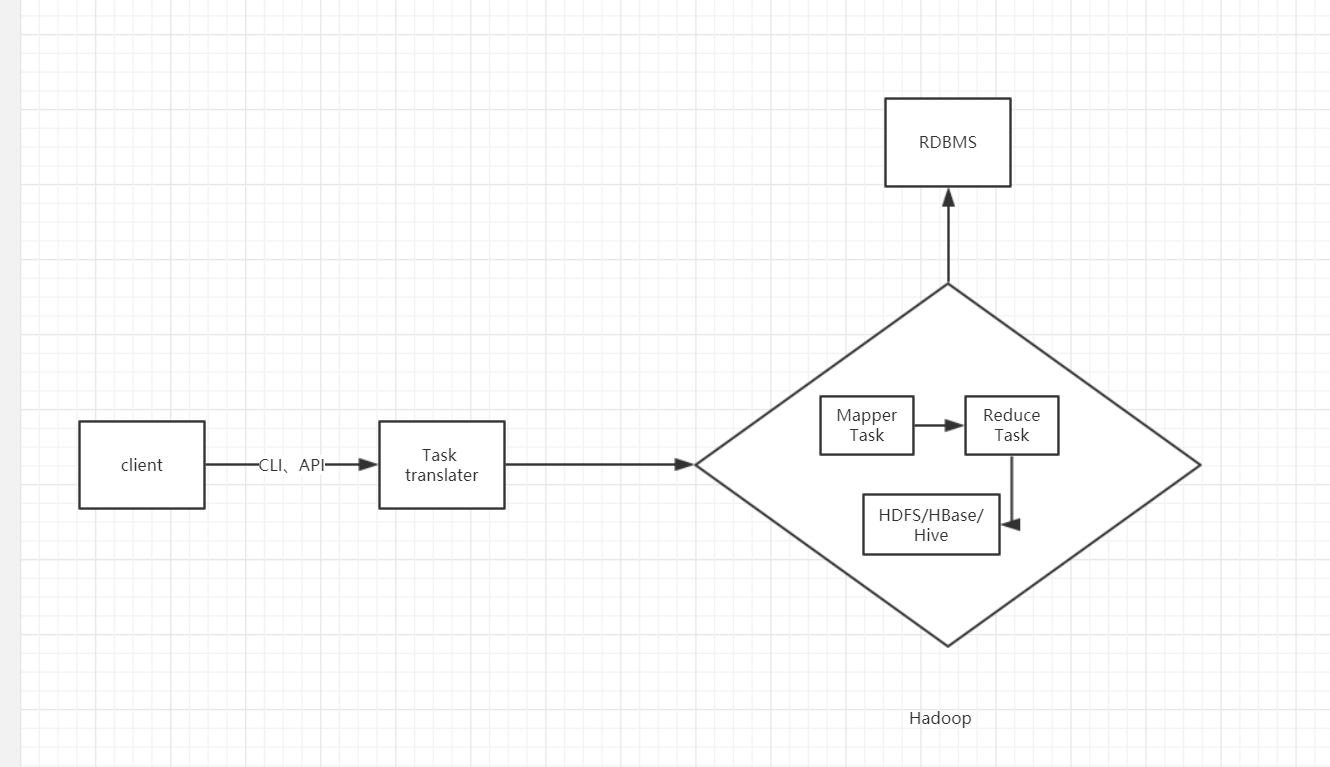
架构图
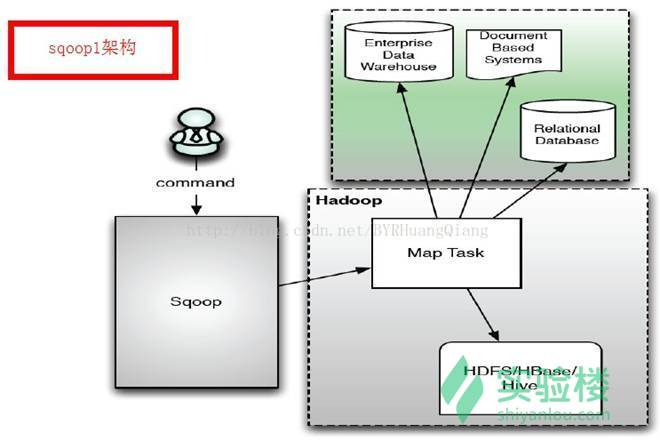
Sqoop 成长至今主要演化了两大版本:Sqoop1 和 Sqoop2。
两个差此外版本,完全不兼容
版本号划分区别,Apache 版本:1.4.x(Sqoop1); 1.99.x(Sqoop2) CDH 版本 : Sqoop-1.4.3-cdh4(Sqoop1) ; Sqoop2-1.99.2-cdh4.5.0 (Sqoop2)
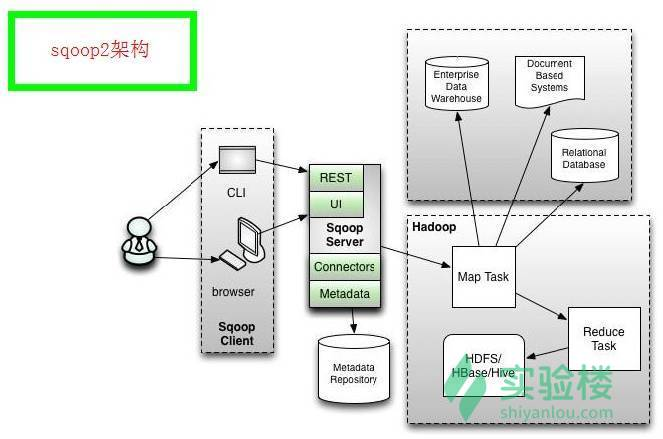
Sqoop2 比 Sqoop1 的改造
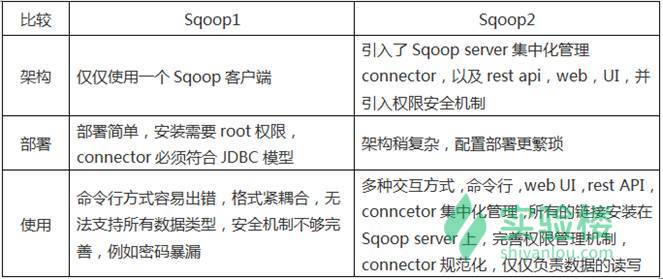
引入 Sqoop server,集中化打点 connector 等
多种访谒方法:CLI,Web UI,REST API
引入基于角色的安适机制
Sqoop 架构图 1
Sqoop 架构图 2:
Sqoop1 与 Sqoop2 的优错误谬误
Flume是Cloudera供给的一个高可用的,高可靠的,漫衍式的海量日志收罗、聚合和传输的系统,Flume撑持在日志系统中定制种种数据发送方,用于收集数据;同时,Flume供给对数据进行简单措置惩罚惩罚,并写到各类数据接受方(可定制)的能力。
当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng颠末重大重构,与Flume-og有很大差别,使用时请注意区分。
Flume最早是Cloudera供给的日志收集系统,是Apache下的一个孵化项目,Flume撑持在日志系统中定制种种数据发送方,用于收集数据。
事情方法 编纂
Flume-og给与了多Master的方法。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于生存配置数据,ZooKeeper自己可保证配置数据的一致性和高可用,此外,在配置数据产生变革时,ZooKeeper可以通知Flume Master节点。Flume Master间使用gossip协议同步数据。
Flume-ng最明显的窜改就是打消了集中打点配置的 Master 和 Zookeeper,变为一个纯粹的传输工具。Flume-ng另一个主要的差别点是读入数据和写出数据由差此外事情线程措置惩罚惩罚(称为 Runner)。 在 Flume-og 中,读入线程同样做写出事情(除了故障重试)。如果写出慢的话(不是完全掉败),它将梗阻 Flume 接收数据的能力。这种异步的设计使读入线程可以顺畅的事情而无需存眷下游的任何问题。
1. Flume可以将应用孕育产生的数据存储到任何集中存储器中,好比HDFS,HBase
2. 当收集数据的速度赶过将写入数据的时候,也就是当收集信息遇到峰值时,这时候收集的信息非常大,甚至赶过了系统的写入数据能力,这时候,Flume会在数据出产者和数据收容器间做出调解,保证其能够在两者之间供给平稳的数据.
3. 供给上下文路由特征
4. Flume的管道是基于事务,保证了数据在传送和接收时的一致性.
5. Flume是可靠的,容错性高的,可升级的,易打点的,并且可定制的。
具有特征 编纂
1. Flume可以高效率的将多个网站处事器中收集的日志信息存入HDFS/HBase中
2. 使用Flume,我们可以将从多个处事器中获取的数据迅速的移交给Hadoop中
3. 除了日志信息,Flume同时也可以用来接入收集规模宏大的社交网络节点事件数据,好比facebook,twitter,电商网站如亚马逊,flipkart等
4. 撑持各类接入资源数据的类型以及接出数据类型
5. 撑持多路径流量,多管道接入流量,,多管道接出流量,上下文路由等
6. 可以被程度扩展
布局 编纂
Agent主要由:source,channel,sink三个组件构成.
Source:从数据产生器接收数据,并将接收的数据以Flume的event格局通报给一个或者多个通道channel,Flume供给多种数据接收的方法,好比Avro,Thrift,twitter1%等
常见类型: :avro 、exec、 jms、spooling directory、source 、kafka 、netcat 等
Channel:温馨提示: 本文由Jm博客推荐,转载请保留链接: https://www.jmwww.net/file/web/29968.html

![[转]Node.js中package.json中^和~的区别](/uploads/allimg/200519/054J34453_lit.png "[转]Node.js中package.json中^和~的区别")